A TM1 cookbook
A TM1 cookbook
This is a collaborative writing effort: users can collaborate writing the articles of the book, positioning the articles in the right order, and reviewing or modifying articles previously written. So when you have some information to share or when you read an article of the book and you didn't like it, or if you think a certain article could have been written better, you can do something about it.
The articles are divided into the following sections defined by roles:
Users
UsersTips for TM1 users:
Cube Viewer tips
Cube Viewer tipsColumns width
When you have a view with a lot of dimensions displayed, it happens that most of the screen estate is consumed by the dimensions columns and you find yourself scrolling a lot left and right to read the data points.
To ease that problem:
-
choose the shortest aliases for all dimensions from the subset editor
-
choose subset names as short as possible
-
uncheck the Options->Expand Row Header
Excel/Perspectives Tips
Excel/Perspectives TipsSynchronising Excel data
. to reduce the probability of crashing your Excel, disable Automatic Calculation : Go to Tools->Options-> Calculation Tab then click on the Manual button
You can use:
- F9 to manually refresh all the open workbooks
- Shift F9 to refresh only the current worksheet
- F2 and Enter key (i.e. edit cell) to refresh only 1 cell
In TM1 9.4.1, the spreadsheets will recalculate automatically when opening a workbook, or changing a SUBNM despite automatic calc is disabled.
From the Excel top menu, click Insert->Name->Define
.In the Define Name dialog box, input TM1REBUILDOPTION
.Set the value in the Refers to box to 0 and click OK.
Avoid multiple dynamic slices
Multiple dynamic TM1 slices in several sheets in a workbook might render Excel unstable and crash. Some references might get messed up too.
E10) Data directory not found
If you are getting the e10) data directory not found popup error when loading Perspectives, you need to define the data directory of your local server, even if you do not want to run a local server.
Go to Files->Options and enter a valid folder in the Data Directory box. if that box is greyed out then you need to edit manually the variable in your tm1p.ini stored on your PC.
DataBaseDirectory= C:\some\path\
Alternatively you can modify the setting directly from Excel with the following VBA code:
Application.Run("OPTSET", "DatabaseDirectory", "C:\some\path")
Publish Views
Publish ViewsPublishing users' view is still far from a quick and simple process in TM1.
First, the admin cannot see other users' views.
Second, users cannot publish their own views themselves.
So publishing views always require a direct intervention from the admin, well not anymore :)
1. create a process with the following code
in Advanced->Parameters Tab
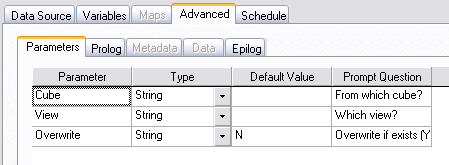
in the Advanced->Prolog Tab
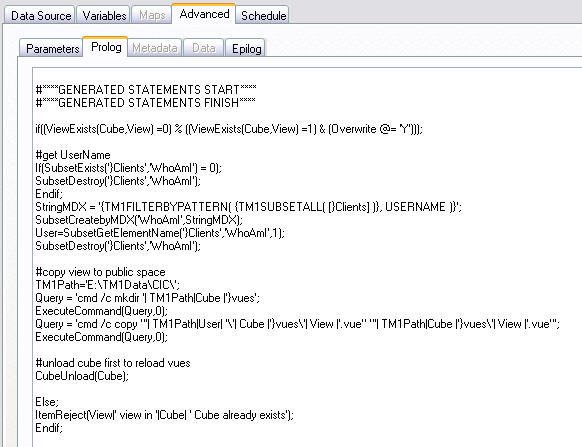
if((ViewExists(Cube,View) =0) % ((ViewExists(Cube,View) =1) & (Overwrite @= 'Y')));
#get UserName
If(SubsetExists('}Clients','WhoAmI') = 0);
SubsetDestroy('}Clients','WhoAmI');
Endif;
StringMDX = '{TM1FILTERBYPATTERN( {TM1SUBSETALL( [}Clients] )}, USERNAME )}';
SubsetCreatebyMDX('WhoAmI',StringMDX);
User=SubsetGetElementName('}Clients','WhoAmI',1);
SubsetDestroy('}Clients','WhoAmI');
#copy view to public space
TM1Path='E:\TM1Data\TM1Server\';
Query = 'cmd /c mkdir '| TM1Path|Cube |'}vues';
ExecuteCommand(Query,0);
Query = 'cmd /c copy "'| TM1Path|User| '\'| Cube |'}vues\'| View |'.vue" "'| TM1Path|Cube |'}vues\'| View |'.vue"';
ExecuteCommand(Query,0);
#unload cube first to reload vues
CubeUnload(Cube);
Else;
ItemReject(View|' view in '|Cube| ' Cube already exists');
Endif;
2. change the TM1Path and save
3. in Server Explorer, Process->Security Assignment, set that process as Read for all groups that should be allowed to publish
Now your users can publish their views on their own by executing this process, they just need to enter the name of the cube and the view to publish.
Alternatively, the code in the above Prolog Tab can be simplified and replaced with these 5 lines:
if((ViewExists(Cube,View) =0) % ((ViewExists(Cube,View) =1) & (Overwrite @= 'Y'))); PublishView(Cube,View,1,1); Else; ItemReject(View|' view in '|Cube| ' Cube already exists'); Endif;
Subset Editor
Subset EditorTree View
To display consolidated elements below their children: View -> Expand Above
Faster Subset Editor
In order to get a faster response from the subset editor, disable the Properties Window:
View -> Properties Window
or click the "Display Properties Window" from the toolbar
Updating an existing subset
to add one or more elements in an existing subset without recreating it:
from the subset editor
- Edit->Insert Subset
- Select the elements
- Click OK to Save as private Subset1
now Subset1 is added to your existing subset
- Expand Subset1
- Click on the Subset1 consolidation element then delete
- You can now save your subset with the new elements
TM1Web
TM1Web- To get cube views to display much faster in tm1web: subsets of the dimensions at the top must contain only 1 element each
- Clicking on the icons in the Export dropdown menu will have no effect, only clicking on the associated text on the right "slice/snapshot/pdf" will start an export
Tracing TM1 references
Tracing TM1 referencesHomemade TM1 reports can get quite convoluted and users might get a hard time updating them as it is difficult to tell where some TM1 formulas are pointing to.
The excel formula auditing toolbar can be useful in such situations.
- right click next to the top bar to bring up the bars menu
- select "Formula Auditing" bar
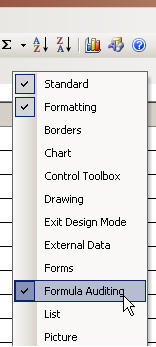
- Activate tracing arrows to highlight precedents
This is quite useful to get the scope of a cube or dimension reference in a report or to see which elements a DBRW formula is made of.
Developers
Developerssection dedicated to Developers
A closer look at dynamic slices
A closer look at dynamic slicesDynamic slices can be quite useful when the elements you display in your reports evolve over time, they automatically update with the new elements.
The following article will try to dig into the parameters that define these slices and show some of the possibilities to interact with these. The idea was originally submitted by Philip Bichard.
The dynamic slice parameters stored in the names list of the worksheet
to display these in Excel: insert -> name -> paste -> paste list
most of the parameters are defined as SLxxCyy
xx is the slice reference 01, 02, 03... for as many slices as there are in the report
yy is the stacked dimension reference
ex: SL01C01 relates to the first stacked dimension on top of columns
SL01C02 relates to the 2nd stacked dimension from the top
SL02R01 relates to the first stacked dimension for rows on the most left of the 2nd slice
CUBE01RNG location of the cell hosting the name of the cube referenced
SL01C01DIMNM subset used or dimension name if not using a saved subset
SL01C01ELEMS_01 list of elements to display
SL01C01EXPANDUP 1/ 0 trigger consolidations as collapsed or expanded
SL01C01FMTNM name of the elements format to use
SL01C01HND ???
SL01C01IDXS_01 ???
SL01C01RNG range for the stacked dimension
SL01CPRX_01 ???
SL01DATARNG range for DBRW cells
SL01FILT filter settings
SL01R01ALIAS name of the alias used
SL01R01DIMNM
SL01R01ELEMS_01 list of elements to be displayed
SL01R01ELEMS_xx ...
SL01R01EXPANDUP
SL01R01HND
SL01R01IDXS_01
SL01R01NM subset name
SL01R01RNG section boundary range
SL01RPRX_01
SL01TIDXS_01 ???
SL01TPRX_01 ???
SL01VIEWHND ???
SL01VIEWIDX ???
SL01ZEROSUPCOL zero suppress on columns trigger
SL01ZEROSUPROW zero suppress on rows trigger
SX01C01ENABLE trigger
SX01C01IDX
SX01C01WD
SX01R01ENABLE trigger
SX01R01HT
SX01R01IDX trigger
SX01RNG section boundary range
SXBNDDSP section boundary display trigger
TITLE1 subnm formula for 1st dimension
TITLE1NM subset
TITLE1RNG cell location
TITLE2
TITLE2NM
TITLE2RNG
TITLE3
TITLE3ALIAS alias to display for the dimension
TITLE3RNG
redefining the following name SL01FILT from
SL01FILT ="FUNCTION_PARAM=0.000000€SORT_ORDER=desc€TUPLE_STR=[Sales Measures].[Sales Units]"
to
SL01FILT ="FUNCTION_PARAM=0.000000€SORT_ORDER=asc€TUPLE_STR=[Sales Measures].[Sales Cost]"
would change the column on which the sorting is made from sales units to sales cost, and also the order from descending to ascending.
One could also achieve a similar result with an MDX expression.
The following code will change the subset from the dimension on the row stack to the predefined "Level Zero Dynamic" subset so all elements will then be displayed.
Sub ChangeRowSubset() ActiveSheet.Names.Add Name:="SL01R01NM", RefersTo:="Level Zero Dynamic" Application.Run "TM1REFRESH" End Sub
Note, you need to use TM1REFRESH or Alt-F9 to get the slice to rebuild itself, TM1RECALC (F9) would only update the DBRW formulas.
Dynamic slices will break with the following popup "No values available" because of some element not existing anymore or not having any values for that specific slice.
An easy fix is to disconnect from the TM1 server, load the report, remove the element causing trouble from the slice and names table, then reconnect to the TM1 server, the dynamic slice will refresh on reconnect just fine.
Attributes
AttributesEdit Attributes...
if you get the following message "This operation accesses a dimension containing a large number of elements. The uploading of these elements from the server may take a few minutes. Continue?"
Editing directly the attributes cube is much faster:
- View -> Display Control Objects
- Open the cube }ElementAttributes_dimension
- Modify the required fields like in any cube
Add new Attribute
for large dimensions, it is faster to just create a temporary TI process with the following code in the Prolog
ATTRINSERT('Model',, 'InteriorColor', 'S');
This example creates the InteriorColor string attribute for the Model dimension.
Checking if an attribute/alias already exists
let's say we want to create an alias Code for the dimension Customer.
In Advanced->Prolog Tab:
If(DIMIX('}Element_Attributes_Customer','Code') = 0);
AttrInsert('Customer','','Code','A');
Endif;
So you do not have to worry about the AttrInsert generating an error if you ever have to run the process again.
After updating aliases in TM1, you will need to clear the Excel cache to see the changes by running the macro m_clear or restart excel.
Bulk reporting
Bulk reportingThe TM1->Print Report function from Perspectives is useful to generate static reports in bulk for a given set of elements.
The following code is mimicking and extending that functionality to achieve bulk reporting for a TM1 report in a more flexible fashion.
For example you could get a report based on the branches of a company to be saved in each respective branch documents folder instead of getting them all dumped in a single folder or you could also get each branch report emailed to its own branch manager.
Here is the Excel VBA code:
Option Explicit
Sub BulkReport()
'http://www.vbaexpress.com/kb/getarticle.php?kb_id=359
'+ admin@bihints mods
'+ some of Martin Ryan code
Dim NewName As String
Dim nm As Name
Dim ws As Worksheet
Dim TM1Element As String
Dim i As Integer
Dim myDim As String
Dim server As String
Dim fullDim As String
Dim total As Long
Dim folder As String
Dim destination As String
destination = "\\path\to\Your Branch Documents\"
server = "tm1server"
myDim = "Store"
fullDim = server & ":" & myDim
If Run("dimix", server & ":}Dimensions", myDim) = 0 Then
MsgBox "The dimension does not exist on this server"
Exit Sub
End If
'loop over all elements of the branch dimension
For i = 1 To Run("dimsiz", fullDim)
TM1Element = Run("dimnm", fullDim, i)
'see if there are any sales for that branch
total = Application.Run("DBRW", Range("$B$1").Value, "All Staff", Range("$B$7").Value, TM1Element, Range("$B$8").Value, "Total Sales")
'process only level 0 elements and sales <> 0 otherwise skip it
If ((Application.Run("ellev", fullDim, TM1Element) = 0) And (total <> 0)) Then
'update the dimension
Range("$B$9").Value = "=SUBNM(""" & fullDim & """, """", """ & TM1Element & """, ""Name"")"
'refresh worksheet
Application.Run ("TM1RECALC")
With Application
.ScreenUpdating = False
' Copy specific sheets
' *SET THE SHEET NAMES TO COPY BELOW*
' Array("Sheet Name", "Another sheet name", "And Another"))
' Sheet names go inside quotes, seperated by commas
On Error GoTo ErrCatcher
'Sheets(Array("Sheet1", "CopyMe2")).Copy
Sheets(Array("Sheet1")).Copy
On Error GoTo 0
' Paste sheets as values
' Remove External Links, Hperlinks and hard-code formulas
' Make sure A1 is selected on all sheets
For Each ws In ActiveWorkbook.Worksheets
ws.Cells.Copy
ws.[A1].PasteSpecial Paste:=xlValues
ws.Cells.Hyperlinks.Delete
Application.CutCopyMode = False
Cells(1, 1).Select
ws.Activate
Next ws
Cells(1, 1).Select
'Remove named ranges except print settings
For Each nm In ActiveWorkbook.Names
If nm.NameLocal <> "Sheet1!Print_Area" And nm.NameLocal <> "Sheet1!Print_Titles" Then
nm.Delete
End If
Next nm
'name report after the branch name
NewName = Left(Range("$B$9").Value, 4)
'Save it in the branch folder of the same name
folder = Dir(destination & NewName & "*", vbDirectory)
ActiveWorkbook.SaveCopyAs destination & folder & "\" & NewName & "_report.xls"
'skip save file confirmation
ActiveWorkbook.Saved = True
ActiveWorkbook.Close SaveChanges:=False
.ScreenUpdating = True
End With
End If
Next i
Exit Sub
ErrCatcher:
MsgBox "Specified sheets do not exist within this workbook"
End Sub
Commenting out portions of code in TI
Commenting out portions of code in TIYou would like to comment out portions of code for legacy or future use instead of removing it. Appending # at the front of every line is ugly and messes up the indenting. Here is a quick, neat and simple fix...
############# PORTION COMMENTED OUT if(1 = 0); #code to comment out is here endif; ####################################
That's it. It can come also handy to turn off auto-generated code in the #****GENERATED STATEMENTS START****.
/!\ I would strongly recommend you add clear markers around the code commented out otherwise it can be very easy for yourself or someone else to overlook the short "if" statement and waste time wondering why the process is not doing anything.
Thanks Paul Simon for the tip.
Creating temporary views
Creating temporary viewswhen creating views from the cube viewer, there is a hard limit to the size of the view displayed. It is 100MB (32bit) or 500MB (64bit) by default, it chan be changed with the MaximumViewSize parameter in the tm1s.cfg
But it is not practical to generate such large views manually.
An alternative is to do it from the Turbo Integrator:
- create a new TI process
- select "TM1 Cube view import"
- click browse
- select the cube
- click create view
from there you can create any view
however it can be more advantageous to create and delete views on-the-fly so your server is cleaner and users will be less confused.
The following code generates a view from the cube 'MyCube' including all elements of the cube.
You need to add some SubsetCreate/SubsetElementInsert in order to limit the view
/!\ remove all consolidations, in most cases they interfere with the import and you will get only a partial import or nothing at all.
--------prolog
CubeName = 'MyCube';
ViewName = 'TIImport';
SubsetName = 'TIImport';
i = 1;
#loop through all dimensions of the cube
while (tabdim(CubeName,i) @<> '');
ThisDim = tabdim(CubeName,i);
If(SubSetExists(ThisDim, SubsetName) = 0);
StringMDX = '{TM1FILTERBYLEVEL( {TM1SUBSETALL( [' | ThisDim | '] )}, 0)}';
#create a subset filtering out all hierarchies
SubsetCreatebyMDX(SubsetName,StringMDX);
EndIf;
i = i + 1;
end;
If(ViewExists(CubeName, ViewName) = 0);
ViewCreate(CubeName, ViewName);
Endif;
i = 1;
#loop through all dimensions of the cube
while (tabdim(CubeName,i) @<> '');
ViewSubsetAssign(CubeName, ViewName, tabdim(CubeName,i), SubsetName);
i = i + 1;
end;
ViewExtractSkipCalcsSet (CubeName, ViewName, 1);
ViewExtractSkipZeroesSet (CubeName, ViewName, 1);
--------------epilog
#cleanup view
ViewDestroy(CubeName, ViewName);
i = 1;
#loop through all dimensions of the cube
while (tabdim(CubeName,i) @<> '');
SubsetDestroy(tabdim(CubeName,i), SubsetName);
i = i + 1;
end;
Debugging
DebuggingAsciiOutput can help tracking what values are being used during execution of your TI processes.
use:
AsciiOutput('\\path\to\debug.cma',var1,var2,NumberToString(var3));
Keep in mind Asciioutput limitations:
- .it is limited to 1024 characters per line
- it can deal only with strings, so you need to apply the NumberToString() function to all numeric variables that you would like to display like var3 in the example above.
- it will open/close the file at every step of the TI. Prolog/Metadata/Data/Epilog that means if you use the same filename to dump your variables in any of these, it will be overwritten by the previous tab process.
Hence you should use different filenames in each tab.
- use DataSourceASCIIQuoteCharacter=''; in the Prolog tab if you want to get rid of the quotes in output.
- use DatasourceASCIIThousandSeparator=''; to remove thousand separators.
- use DatasourceASCIIDelimiter='|'; to change from ',' to '|' as separators
Alternatively you can use ItemReject if the record you step through is rejected, it will then be dumped to the error message
ItemReject(var1|var2);
Use DatasourceASCIIDelimiter to
Dynamic SQL queries with TI parameters
Dynamic SQL queries with TI parametersIt is possible to use parameters in the SQL statement of Turbo Integrator to produce dynamic ODBC queries
Here is how to proceed:
1. create your TI process
2. Advanced->Parameters Tab, insert parameter p0
3. Advanced->Prolog Tab add the processing code to define parameter p0
example: p0 = CellGetS(cube,dim1,dim2...)
4. save the TI process
5. open Data Source, add parameter p0 in WHERE clause
example select * from lib.table where name = '?p0?'
DO NOT CLICK ON THE VARIABLES TAB AT ANY TIME
6. run, answer "keep all variables" when prompted
If you need numeric parameters, there is a twist! numeric parameters do not work! (at least for TM1 9.x)
example: select * from lib.customer where purchase > ?p0? will fail although p0 is defined as a numeric and quotes have been removed accordingly.
But fear not, there is a "simple" workaround
1. proceed as above up to step 5
2. Advanced->Prolog tab, at the bottom: strp0 = NumberToString(p0);
3. Data Source tab, in the SQL statement replace ?p0? with CAST('?strp0?' as int)
example: select * from lib.customer where purchase > ?p0?
becomes select * from lib.customer where purchase > CAST('?strp0?' as int)
clicking the preview button will not show anything but the process will work as you can verify by placing an asciioutput in the Advanced->Data tab.
The CAST function is standard SQL so that should be working for any type of SQL server.
Note from Norman Bobo:
It is not necessary to add the "CAST" function to the SQL to pass numeric values. The trick is to think of the parameter as a substitution string, not a value. Define the parameter as a string and insert it into the SQL embedded in ?'s. When setting the value in the Advanced Prolog tab, convert the numeric value you would like to use into a string value. That value will be simply substituted into the SQL statement directly, as if you typed the value into the SQL yourself.
For instance:
In the Advanced/Prolog tab:
strFY = NUMBERTOSTRING(CELLGETN('Control Cube','FYElem','ControlValue');
Parameter:
Name: strFY, datatype: string, Default value: 2010, Prompt: Enter the FY:
In the SQL:
...
where FY = ?strFY?
Dynamic formatting
Dynamic formattingIt is possible to preformat dynamic slices by using the Edit Element Formats button in the subset editor. However that formatting is static and will not apply to new elements of a slowly changing dimension. Also it takes a long time to load/save when you try to apply it to more than a few dozen elements.
As an example, we will demonstrate how to dynamically alternate row colors in a TM1 report for a Customer dimension.
.Open subset editor for the Customer dimension
.Select some elements and click "Edit Elements Format"
.the "Edit Element Formats" worksheet opens, just click Save as "colored row"
this creates the }DimensionFormatStyles_Customer dimension and the }DimensionFormats_Customer cube.
Now we can modify this cube with our rules.
open the rules editor for the }DimensionFormats_Customer cube, add this:
#alternate row colors for all elements
['colored row','Cond1Type'] = S: '2';
['colored row','Cond1Formula1'] = S: '=MOD(ROW(),2)=1';
['colored row','Cond1InteriorColorIndex'] = S: '34';
['colored row','Cond2Type'] = S: '2';
['colored row','Cond2Formula1'] = S: '=MOD(ROW(),2)=0';
['colored row','Cond2InteriorColorIndex'] = S: '2';
now slice a view with the Customer dimension, applying that "colored row" style.
result:
To create a different style:
- Edit one element from the "Edit element format", apply the desired formatting and save
- Note the new values of the measures in the }DimensionFormats_Customer cube for that element
- Reflect these changes in the rules to apply to all elements for that style
Padding zeroes
Padding zeroesThis a short simple syntax to easily pad zeroes to an index value:
Period = 'Period ' | NumberToStringEx(index, '00','','');
(from olap forums)
alternatively, one could also write (prior to TM1 8.2):
Period = 'Period ' | If(index > 10,'0','') | NumberToString(index);
Renaming elements
Renaming elementsRenaming elements without activating aliases? Yes we can!
The dimension editor and dimension worksheets cannot rename elements directly, so let me introduce you to SwapAliasWithPrincipalName.
In this example, we will add a padding "0" to an existing set of elements without rebuilding the dimension from scratch.
Before swap:

- Create a new alias "new" in the Dimension, by default the new elements are identical
- Change all required elements to their new names in that alias. Below we pad a zero in front of all elements
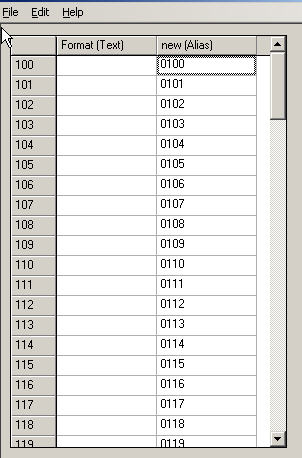
Now create a new TI with the following line in the Prolog Tab:
SwapAliasWithPrincipalName(Dimension,'new',0);
The third parameter needs to be zero to execute the swap. If you know if it has any purpose, please leave a comment to enlighten us.
After swap:

And the "old" elements have become the "new" alias:
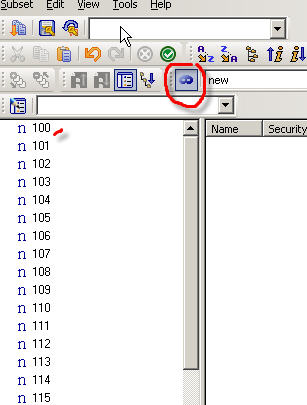
/!\Make sure the associated dimension worksheet is also updated if there is one!!!
This was tested successfully under v. 9.0.3 and v. 9.4.
This TI function is listed in the TM1 documentation, however there is no description of its function and syntax.
Click on the RTFM FAIL tag to find out some other poorly documented or simply undocumented TM1 functions.
Rules
RulesDimension elements containing a single quote character (') require a double quote to be interpreted correctly by the rules engine.
Example: ['department's'] -> ['department''s']
One could use aliases without single quote characters too, however the rule would break if anything were to happen to these aliases. So it is best practice not to use single quote characters in your elements in the first place and if you really need them, then use the double quote in the rules.
After modifying cells through rules, the consolidations of these cells won't match the new values.
To reconciliate consolidations add in your rules:
['Total'] = ConsolidateChildren('dimension')
Scheduling chores on calendar events
Scheduling chores on calendar eventsRunning chores on a specific day of the month
Scheduling chores in TM1 can be frustrating as it does not offer to run on specific dates or other types of events. The following article explains how to create chores schedules as flexible as you need them to be.
From the Server Explorer
- Create a new process
- Click Advanced ->Prolog tab
- Add this code:
#run chore every 1st day of the month If(SUBST(TODAY,7,2)@<>'01'); ChoreQuit; Endif;
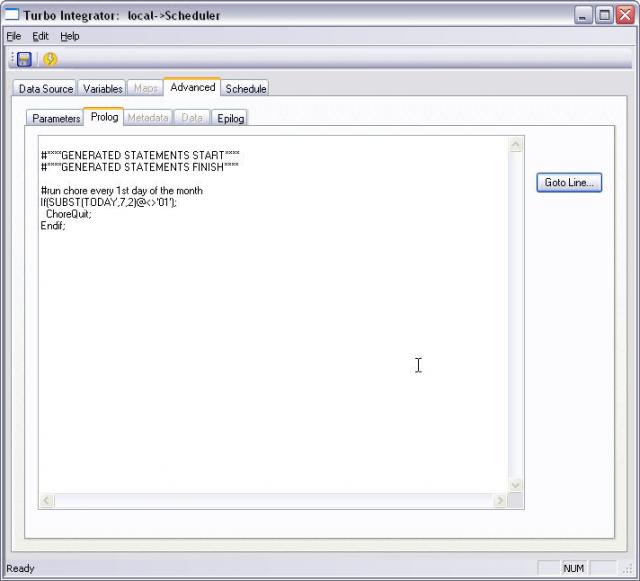
- Save the process as "Scheduler"
- Create a new chore
- Select "Scheduler" and the other process(es) that you need to run
- It is important to put the "Scheduler" process first in the list
- Set it to run once a day
You are now set: that chore will run every first day of the month.
The ChoreQuit command will abort the "Scheduler" process and the subsequent processes in the chore list if today's date is not "01" i.e. the first day of the month.
From the above code you see that you can actually get your chore to run based on any sort of event, all you need is to change the conditional statement to the desired event.
Running chores on specific days of the week
DayOfWeek= Mod ( DayNo( TODAY ) + 21915, 7);
# 0 = Sunday, 1 = Monday to 6 = Saturday.
If( DayOfWeek = 0 % DayOfWeek > 4 );
ChoreQuit;
Send email/attachments
Send email/attachmentsIt is possible to send email alerts or reports as attachments from Turbo Integrator. This can be achieved by executing a VB script.
- Save the attached VB script on your TM1 server
- Create a TI process
- In the Epilog tab, add the following code:
S_Run='cmd /c D:\path\to\SendMail.vbs smtp.mycompany.com 25 tm1@mycompany.com me@mycompany.com "Today report" "check it out" E:\TM1Reports\todaysreport.xls'
ExecuteCommand(S_Run,0);
The syntax is:
SendMail.vbs server port sender destination subject body attachment
so replace the fields as required to suit your setup
/!\ The DOS command line is limited to 255 characters so avoid putting too much information in the body.
/!\ If a field contains a blank space you must enclose that field in quotes so the script gets the correct parameters
code from kc_kang (applix forum) available at https://web.archive.org/web/20120620123310/http://www.rondebruin.nl/cdo.htm
Silent failures
Silent failuresTM1 processes will not complain when their input source is empty.
So although the "process successful" or "chore successful" message will popup, your cube will remain desperately empty.
In order to solve that silent bug (or rather "feature" in IBM's eyes), you will need to add specific code to your TI processes to test against empty sources.
Here follows:
.initialise counter
PROLOG TAB
SLineCount = 0; #****GENERATED STATEMENTS START****
.increment counter
DATA TAB
SLineCount = SLineCount + 1; #****GENERATED STATEMENTS START****
.check counter value at the end and take appropriate action
EPILOG TAB
if(SLineCount = 0);
ItemReject('input source ' | DataSourceType | ' ' | DataSourceNameForServer | ' is empty!');
endif;
#****GENERATED STATEMENTS START****
ItemReject will send the error to the msg log and the execution status box will signal a minor error.
TM1 lint
TM1 lintalias.pl is a very basic lint tool whose task is to flag "dangerous" TM1 rules.
For now it is only checking for aliases in rules.
Indeed, if an alias is changed or deleted, any rule based on that alias will stop working without any warning from the system. The values will remain in place until the cube or its rules gets reloaded but you will only get a "silent" warning in the messages log after reloading the cube.
How to proceed:
.configure and execute the following TI process (to put in prolog), this will generate a list of all cubes and associated dimensions, and a dictionary of all aliases on the system in .csv format
### PROLOG
#configure the 2 lines below for your system
report = 'D:\alias.dictionary.csv';
report1 = 'D:\cubes.csv';
#
##############################################
#it is assumed that none of the aliases contain commas
DataSourceASCIIQuoteCharacter = '';
######create a list of all cubes and associated dimensions
c = 1;
while(c <= DimSiz('}Cubes'));
cube = DIMNM('}Cubes',c);
d = 1;
while(tabdim(cube,d) @<> '');
asciioutput(report1, cube, tabdim(cube, d));
d = d + 1;
end;
c = c + 1;
end;
######create a dictionary of all aliases
d = 1;
while(d <= DimSiz('}Dimensions'));
dim = DIMNM('}Dimensions',d);
#skip control dimensions
If(SUBST(dim,1,1) @<> '}');
attributes = '}ElementAttributes_' | dim;
#any aliases?
If(DIMIX('}Dimensions',attributes) <> 0);
a = 1;
while(a <= DimSiz(attributes));
attr = DIMNM(attributes,a);
#is it an alias?
If(DTYPE(attributes,attr) @= 'AA');
#go through all elements and report the ones different from the principal name
e = 1;
while(e <= DimSiz(dim));
element = DIMNM(dim,e);
If(element @<> ATTRS(dim,element,attr) & ATTRS(dim,element,attr) @<> '');
asciioutput(report,dim,attr,ATTRS(dim,element,attr));
Endif;
e = e + 1;
end;
Endif;
a = a + 1;
end;
Endif;
Endif;
d = d + 1;
end;
.configure and execute the perl script attached below
that script will load the csv files generated earlier in hash tables, scan all rules files and finally report any aliases.
If the element is ambiguous because it is present in 2 different dimensions then you should write it as dimension:'element' instead of using aliases (e.g. write Account:'71010' instead of '71010').
Pimp my PAW
Pimp my PAW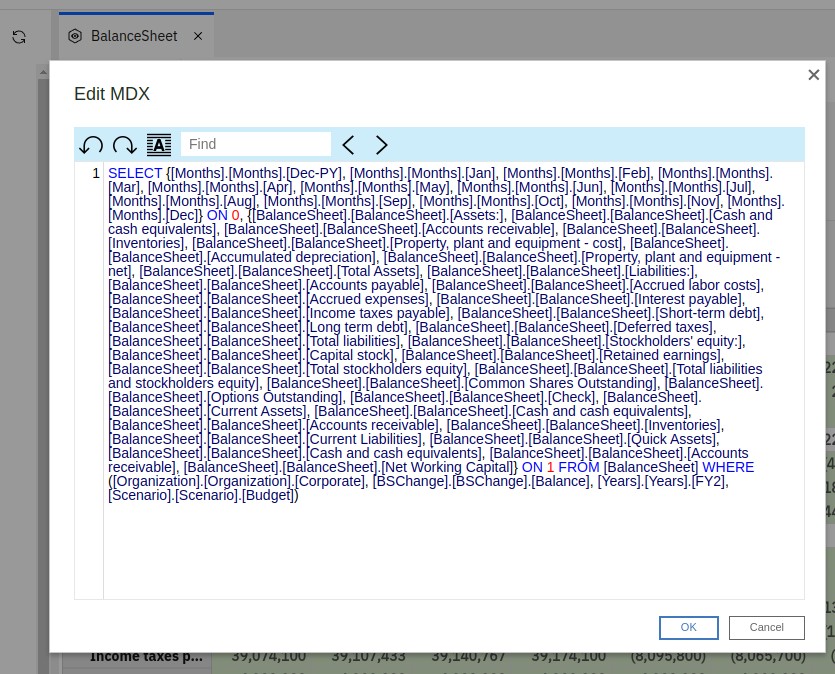
I'm in the PAW Workbench, I open a view and I click on the "Edit MDX" button. I get a packed MDX block, with no indentation whatsoever, pretty hard to read. If only there was an option to format that MDX block to something much easier to read.....
**RING** **RING** Oh, I'm sorry, I must interrupt this blogpost, someone is at the door.
Please hold on.
- I'm sorry, who are you?
- Yo dawg! I'm Xzibit!
- Wait! What? What are you doing on this blog?
- Yo dawg I herd you like APIs so we put an API in yo API so you can MDX while you MDX.

- Is this a joke? This does not make any sense!
- It will make sense, buckle up yo.
This is going to be the setup:
chromium <---mitmproxy---> PAW server
- chromium opens the MDX Editor, that triggers a POST /api/v1/MDX call to the PAW server
- mitmproxy catches the json response from the PAW server
- a python script modifies that json data on-the-fly according to our needs
- mitmproxy hands over the modified data to chromium
- finally chromium displays the reformatted MDX expression
The whole process is completely transparent to the client and the server. We are inserting ourselves in the middle of an SSL encrypted connection, it will require installing a fake Certificate Authority to keep both client and server happy. And I don't like clicking around, so we will prepare that setup from the commandline.
First, we install the mdx-beautify.py script that mitmproxy will be using to process the PAW server responses.
mkdir ~/.mitmproxy && cat > ~/.mitmproxy/mdx-beautify.py << EOF
from sql_formatter.core import format_sql
from mitmproxy import http
import json
def response(flow: http.HTTPFlow) -> None:
#intercept MDX API responses
if flow.request.pretty_url.endswith("/api/v1/MDX"):
content = json.loads(flow.response.content)
mdx_pretty = format_sql(content['Mdx'])
# inject the expression back in the flow
content['Mdx'] = mdx_pretty
flow.response.content = bytes(json.dumps(content),"UTF-8")
EOF
#
Before installing the mitmproxy/mitmproxy docker image, we need to extend that docker image with the python package "sql formatter". sql formatter is not ideal to format MDX, but that will be good enough for the sake of that proof of concept:
docker build --tag mitmproxy-sqlfmt - << EOF FROM mitmproxy/mitmproxy RUN pip install sql_formatter EOF #
Now run that new build with the mdx-beautify.py script and a localhost web interface on port 8081 to display what goes through the proxy:
docker run --rm -it -p 8080:8080 -p 127.0.0.1:8081:8081 -v ~/.mitmproxy:/home/mitmproxy/.mitmproxy mitmproxy-sqlfmt mitmweb -s ~/.mitmproxy/mdx-beautify.py --web-host 0.0.0.0
On its first run, the container generates all the necessary certificates in ~/.mitmproxy .
With a browser, navigate to http://127.0.0.1:8081 this is mitmweb interface that allows you to see all the exchanges between the client and PAW server. We will not use that browser to access the PAW server, this is only to watch what's happening in the background.
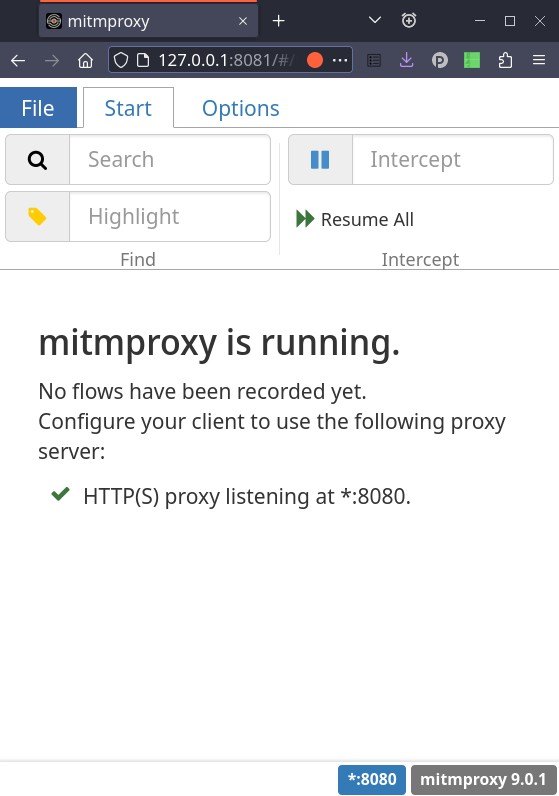
As it is suggested on that screenshot, we will now configure a chromium client to use that proxy.
But first, a word of warning, installing fake CAs is messy, and it creates a huge security vulnerability in your browser, anybody in possession of the CA keys could read the traffic from your browser. So, we are going to sandbox chromium with firejail in order to keep that setup isolated in a dedicated directory ~/jail and that will be much easier to clean up afterwards.
We initialise the certificates database in the jail with certutil from mozilla-nss-tools and populate it with the newly generated mitmproxy certificate. That will spare us from messing with the browser settings at chrome://settings/certificates
mkdir -p ~/jail/.pki/nssdb && certutil -d sql:$HOME/jail/.pki/nssdb -A -t "CT,c,c" -n mitmproxy -i ~/.mitmproxy/mitmproxy-ca-cert.pem
We launch the sandboxed chromium in firejail with the preconfigured proxy address
firejail --env=https_proxy=127.0.0.1:8080 --private=~/jail chromium
With this jailed chromium, navigate to the URL where your PAW server is located, log in, open the workbench and open some cube view, as you normally would.
Now, you see on the screenshot below, on the bottom left, clicking on the "Edit MDX" button resulted in a POST /api/v1/MDX call to the PAW server. On the right, in the response from the server, the value for the key "Mdx" is correctly showing "\n" and space indentations. And finally, the "Edit MDX" window is showing the MDX expression almost formatted to our liking.
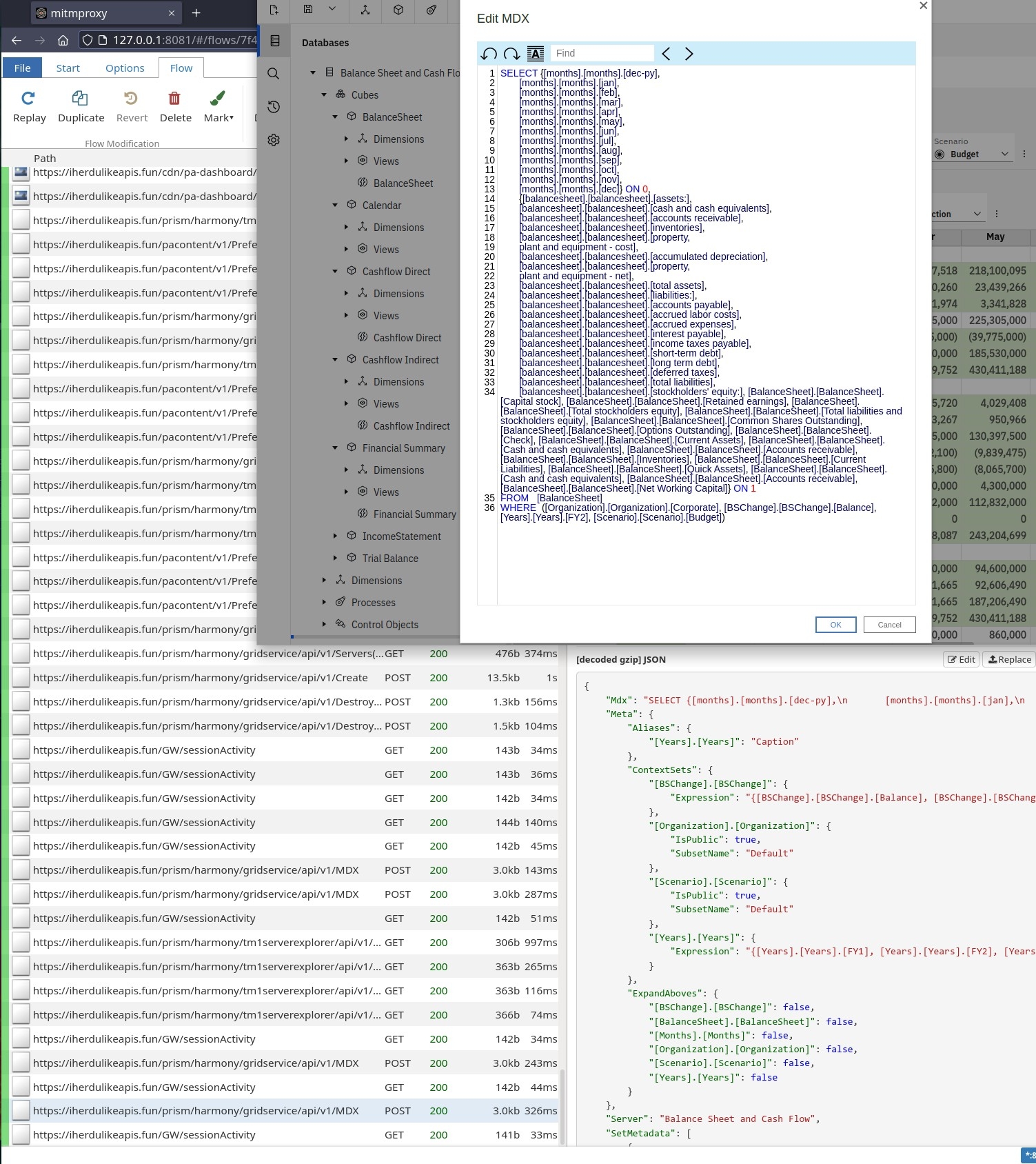
- OK! But this is definitely not something that I would deploy to users.
- Right yo! This setup is only intended for educational purposes, and it is about as useful as print "hello world!". But It gives you a different approach to dig in the PAW API, and a way to inject it with python code through the mitmproxy scripting API.
- Thanks Xzibit!
TM1 operators
TM1 operatorsLogical operators
& AND
% OR
~ NOT
Strings operators
| concatenate
@= string1 equals string2
@<> string1 differs from string2
inserting '&' in strings:
ItemReject('This & That'); will return 'This _That'
ItemReject('This && That'); will return 'This & That'
Creating Dynamic Subsets in Applix TM1 with MDX - A Primer
Creating Dynamic Subsets in Applix TM1 with MDX - A PrimerLead author: Philip Bichard.
Additional Material: Martin Findon.
About This Document
This MDX Primer is intended to serve as a simple introduction to creating dynamic dimension subsets using MDX in TM1. It focuses on giving working examples rather than trying to explain the complete theory of MDX and makes sure to cover the features most useful to TM1 users.
TM1 currently (as of 9.0 SP3) only allows users to use MDX to create dimension subsets and not to define cube views. This means that the usage of MDX in TM1 is often quite different in terms of both syntax and intention from examples found in books and on the internet.
As MDX (Multi-Dimensional eXpressions) is an industry-standard query language for OLAP databases from Microsoft there are many references and examples to be found on the Internet, though bear in mind that TM1 doesn’t support every aspect of the language and adds a few unique features of its own. This can make it difficult to use examples found on the web, whereas all the examples in this document can simply be copied-and-pasted into TM1 and will execute without modification, assuming you have the example mini-model created as documented later.
Full document as just one HTML page here.
What is a MDX-based dynamic subset in TM1?
What is a MDX-based dynamic subset in TM1?A dynamic subset is one which is not a fixed, static, list but instead it is based on a query which is re-evaluated every time the subset is used. In fact, MDX could be used to create a static subset and an example is shown below, but this unlikely to be useful or common.
Some examples of useful dynamic subsets might be a list of all base-level products; a list of our Top 10 customers by gross margin; a list of overdue supply shipments; all cost centres who have not yet submitted their budget. The point is, these lists (subsets) may vary from second to second based on the structure or data in TM1. For example, as soon as a new branch is added to Europe, the European Branches subset will immediately contain this new branch, without any manual intervention needed.
MDX is the query language used to define these subsets. MDX is an industry-standard query language for multi-dimensional databases like TM1, although TM1 only supports a certain subset (excuse the pun) of the entire language and adds in a few unique features of its own as well. When you define a subset using MDX instead of a standard subset, TM1 stores this definition rather than the resulting set. This means the definition – or query – is re-run every time you look at it – without the user or administrator needing to do anything at all. If the database has changed in some way then you may get different results from the last time you used it. For example, if a subset is defined as being “the children of West Coast Branches” and this initially returns “Oakland, San Francisco, San Diego” when it is first defined, it may later return “Oakland, San Francisco, San Diego, Los Angeles” once LA has been added into the dimension as a child of West Coast Branches. This is what we mean by “dynamic” – the result changes. Another reason that can cause the subset to change is when it is based on the values within a cube or attribute. Every day in the newspaper the biggest stock market movers are listed, such as a top 10 in terms of share price rise. In a TM1 model this would be a subset looking at a share price change measure and clearly would be likely to return a different set of 10 members every day. The best part is that the subset will update its results automatically without any work needed on the part of a user.
How to create a MDX-based subset in TM1
How to create a MDX-based subset in TM1The same basic steps can be followed with all the examples in this document. Generally the examples can be copy-and-pasted into the Expression Window of the Subset Editor of the dimension in question – often Product. Note that it is irrelevant which cube the dimension is being used by; you will get same results whether you open the dimension Subset Editor from within a cube view, the cube tree in Server Explorer or the dimension tree in Server Explorer.
In order to view and edit an MDX query you must be able to see the Expression Window in the Subset Editor. To toggle this window on and off choose View / Expression Window.
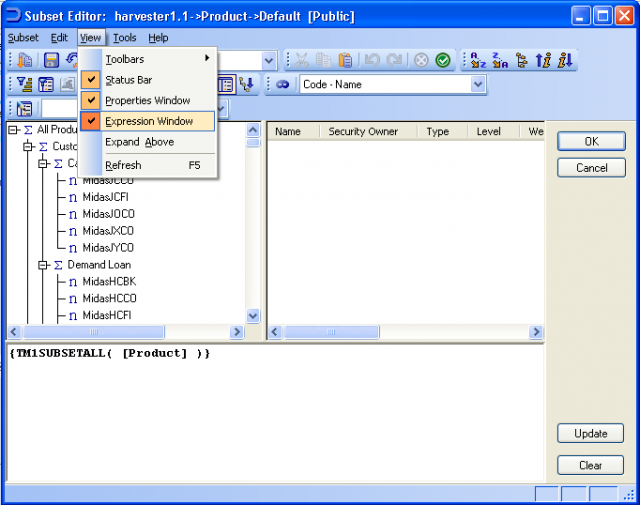
You can now just type (or paste) your query into this Expression Windows and press the Update button to see the results.
How to create a static subset with MDX
How to create a static subset with MDXA static subset is one which never varies in its content.
This query will return the same 3 members (Discount Loan, Term Loan and Retail) every time.
{ [Product].[Discount Loan], [Product].[Term Loan], [Product].[Retail] }
Don’t worry, it gets more exciting from here.
How to create a dynamic subset with MDX
How to create a dynamic subset with MDXTM1 only supports a certain number of functions from the complete MDX specification. Different versions of TM1 will support different functions (and potentially support the in different ways). The valid set of functions for the version of TM1 that you are using can be found in the main Help file, under Reference Material / MDX Function Support. Before trying to write a new query, make sure it is supported, and although some unlisted functions certainly do work they must be used at your own risk. The standard error message which means the function is genuinely not supported by your version of TM1 is, "Failed to compile expression".
One word of warning: by its very nature, the results of a dynamic subset can change. When including dynamic subsets in views, processes, SUBNM functions, and so forth, consider carefully what the potential future results might be, especially if the subset could one day be empty.
The two most common methods to go about actually creating a dynamic subset are to create them by hand or using TurboIntegrator.
By hand. You can either type (or paste) a query into the Expression Window as explained earlier, or you can choose Tools / Record Expression (and then Stop Recording when done) to turn on a kind of video recorder. You can then use the normal features of the subset editor (e.g. select by level, sort descending, etc.) and this recorder will turn your actions into a valid MDX expression. This is a great way to see some examples of valid syntax, especially for more complex queries.
When you have been recording an expression and choose Stop Recording TM1 will ask you to confirm if you wish to attach the expression with the subset - make sure to say ‘Yes’ and tick the ‘Save Expression’ checkbox when saving the resulting subset, otherwise only a static list of the result is saved, not the dynamic query itself.
Using TurboIntegrator. Only one line, using SubsetCreateByMDX, is needed to create and define the subset. You will need to know what query you want as the definition already. Note that the query can be built up in the TI script using text concatenation so can incorporate variables from your script and allow long queries to be built up in stages which are easier to read and maintain.
SubsetCreatebyMDX('Base Products','{TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )}, 0)}');
All TI-created MDX subsets are saved as dynamic MDX queries automatically and not as a static list.
Note that, at least up to TM1 v9.0 SP3, MDX-based subsets cannot be destroyed (SubsetDestroy) if they are being used by a public view, and they cannot be recreated by using a second SubsetCreateByMDX command. Therefore it is difficult to amend MDX-based subsets using TI. While the dynamic nature of the subset definition may make it somewhat unlikely you will actually want to do this, it is important to bear in mind. If you need to change some aspect of the query (e.g. a TM1FilterByPattern from “2006-12*” to “2007-01*” you may have to define the query to use external parameters, as documented in this document. This will have a small performance impact over the simpler hardcoded version.
Also, filter against values of a cube with SubsetCreateByMDX in the Epilog tab e.g. {FILTER({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},[Test].([Posting Measures].[Amount]) > 0 )} will not work if the values happen to have been loaded in the Data tab. You need to execute the SubsetCreateByMDX command in a subsequent TI process.
Note that TI has a limit of 256 characters for defining MDX subsets, at least up to v9.1 SP3, which can be quite limiting.
Syntax and Layout
Syntax and LayoutA query can be broken over multiple lines to make it more readable. For example:
{
FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
Test2.([Rate Measures].[Rate]) = 19
)
}
is more readable than having the whole query in one line. The actual filter section is more easily read and modified now by having it on a line by itself.
Note that references to members usually have the dimension name as a prefix. For example,
{ {[Product].[Retail].Children} }
In fact the dimension name is optional – but only if the member name (Retail in this case) is completely unique within the entire server - i.e. there are no cubes, dimensions or members with that exact name. For example this is the same query with the dimension name omitted:
{ {[Retail].Children} }
Which would work in the context of the sample application used by this document but would be risky in a real-world application. The error message received when forgetting to specify the prefix would be something like, “Level or member name “[Retail]” ambiguous: found in dimensions…” and then it goes on to list the various dimensions in which the non-unique member name can be found, which is very helpful. It is therefore certainly safest and most performant to always use the dimension prefix.
The use of square brackets can sometimes seem a bit arbitrary when reading examples of MDX queries. The fact is that an OLAP object name (e.g. cube name, dimension name, member name) must be enclosed in square brackets only if it contains a space, starts with a number or is an MDX reserved word (e.g. Select). However, sometimes it can be simpler to decide to always use brackets so similar queries can be compared side by side more easily.
The exact definition of a member in TM1 is almost always expressed as [Dimension Name].[Member Name] and no more. In other products that also use MDX as a query language (such as Microsoft Analysis Services) you may notice that queries specific the full ‘path’ from the dimension name through the hierarchy down to the member name, for example:
[Date].[2009].[Q1].[Feb].[Week 06]
This can also be written as [Date].[2009^Q1^Feb^Week 06]
The reason for this is that other products may not require every member name to be unique since each member has a context (it’s family) to enable it be uniquely identified, which is why they need to know exactly which Week 06 is required since there may be others (in 2008 for instance in the above example). TM1 requires all member names, at any level (and within Aliases) to be completely unique within that dimension. TM1 would need you to make Q1, Feb and Week 06 more explicit in the first place (i.e. Q1 2009, Feb 2009, Week 06 2009) but you can then just refer to [Date].[Week 06 2009].
Finally, case (i.e. capital letters versus lower case) is not important with MDX commands (e.g. Filter or FILTER, TOPCOUNT or TopCount are all fine) but again you may prefer to adopt just one style as standard to make it easier to read.
The example model used
The example model usedIn this document many examples of dynamic queries will be given. They all work (exactly as written, just copy-and-paste them into the Expression Window in the Subset Editor of the appropriate dimension to use them) on the simple set of cubes and dimensions shown below. The model is deliberately simple with no special characteristics so you should find it easy to transfer the work to your own model.
The model used included 1 main dimension, Product, on which the vast majority of the queries works plus 3 cubes: Test, Test2 and Test3. The data values in the cubes will vary during testing (you’ll want to tweak the values and re-run the query to make sure the results change and are correct) but the screenshots below show the cube and dimension structures well enough for you to quickly recreate them or how to use your own model instead. To simplify the distribution of this document there is no intention to also distribute the actual TM1 model files. Note that the main dimension used, Product, featured ragged, and multiple, hierarchies.
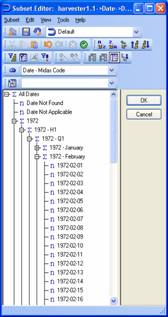
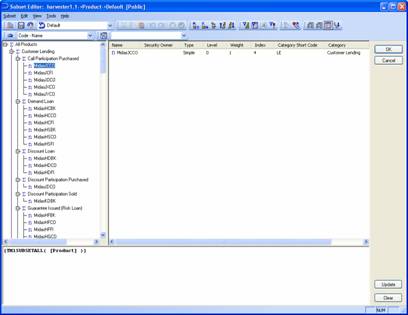
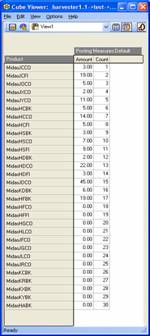
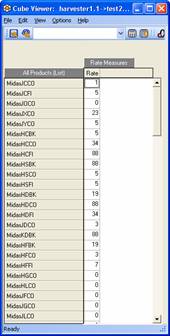
TM1SubsetAll, Members, member range
TM1SubsetAll, Members, member rangeThe basis for many queries, this returns (almost, see below) the entire dimension, which is the equivalent of clicking the ‘All’ button in the Subset Editor.
TM1SUBSETALL( [Product] )
Note that only the final instance in the first hierarchy of members that are consolidated multiple times is returned.
The Members function, on the other hand, delivers the full dimension, duplicates included:
[Product].Members
A range of contiguous members from the same level can be selected by specifying the first and last member of the set you require with a colon between them.
This example returns Jan 1st through to Jan 12th 1972.
{[Date].[1972-01-01]:[Date].[1972-01-12]}
Select by Level, Regular Expression (Pattern) and Ordinal
Select by Level, Regular Expression (Pattern) and OrdinalSelecting members based on their level in the dimension hierarchy (TM1FilterByLevel) or by a pattern of strings in their name (TM1FilterByPattern) can be seen easily by using the Record Expression feature in the subset editor.
The classic “all leaf members” query using TM1’s level filtering command TM1FilterByLevel:
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}
Select all the leaf members which match the wildcard ‘*HC??’ – i.e. that have H and C as the third and fourth characters from the end of their name.
{TM1FILTERBYPATTERN( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, "*HC??")}
The reason that these functions start with “TM1” is that they are not standard MDX commands and are unique to TM1. There are two main reasons why Applix will implement such unique functions: to add a feature that is present in “standard” TM1 and users will miss if it is not there; or because “standard” TM1 has the same feature as MDX but has historically implemented it slightly differently to MDX and therefore would, again, cause users problems if it was only implemented in the standard MDX way.
In these two cases, TM1FilterByPattern brings in a function commonly used by TM1 users that is lacking in MDX, while TM1FilterByLevel exists because TM1 has, since its launch in 1984, numbered consolidation levels starting at zero for the leaf level rising up the levels to the total members, while Microsoft decided to do it the exact opposite way.
In certain situations it is useful to use the standard MDX levels method and this is also available with the Levels function. It allows you return the members of a dimension that reside at the same level as a named member, just bear in mind that standard MDX orders the levels in terms of their distance from the top of the hierarchy and not the bottom as TM1.
This example returns all the members at the same level as the Retail member:
{ {[Product].[Retail].Level.Members} }
Which, although Retail is a high level consolidation, returns an N: item (Product Not Applicable) in the dimension because this rolls straight up into All Products as does Retail so they are considered to be at the same level.
To filter the dimension based on a level number you need to use the .Ordinal function. This is not documented as being supported in the Help file, and did not work in 8.2.7, but appears to work in 9.0 SP3 and 9.1.1.36 at least.
This example returns all the members at Level 1:
{Filter( {TM1SUBSETALL( [Product] )}, [Product].CurrentMember.Level.Ordinal = 1)}
This example would return all members not at the same level as Discount Loan.
{Filter( {TM1SUBSETALL( [Product] )}, [Product].CurrentMember.Level.Ordinal <> [Product].[Discount Loan].Level.Ordinal)}
TM1Sort, TM1SortByIndex and Order
TM1Sort, TM1SortByIndex and OrderTM1Sort is the equivalent of pressing one of the two Sort Ascending or Sort Descending buttons in the subset editor – i.e. sort alphabetically.
TM1SortIndex is the equivalent of pressing one of the two Sort by index, ascending or Sort by index, descending buttons in the subset editor – i.e. sort by the dimension index (dimix).
Order is a standard MDX function that uses a data value from a cube to perform the sort. For example, sort the list of customers according to the sales, or a list of employees according to their length of service.
Sort the whole Product dimension in alphabetically ascending order.
{TM1SORT( {TM1SUBSETALL( [Product] )}, ASC)}
Or, more usefully, just the leaf members:
{TM1SORT( TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )},0), ASC)}
Sort the leaf members according to their dimix:
{TM1SORTBYINDEX( TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )},0), ASC)}
Sort the leaf members of the dimension according to their Amount values in the Test cube from highest downwards.
{
ORDER(
{ TM1FILTERBYLEVEL(
{TM1SUBSETALL( [Product] )}
,0)}
, [Test].([Posting Measures].[Amount]), BDESC)
}
Note that using BDESC instead of DESC gives radically different results. This is because BDESC treats all the members across the set used (in this case the whole dimension) as being equal siblings and ranks them accordingly, while DESC treats the members as still being in their “family groups” and ranks them only against their own “direct” siblings. If you’re not sure what this means and can’t see the difference when you try it out, then just use BDESC!
Order can also use an attribute instead of a cube value. In this example the AlternateSort attribute of Product is used to sort the children of Demand Loan in descending order. It is a numeric attribute containing integers (i.e. 1, 2, 3, 4, etc) to allow a completely dynamic sort order to be defined:
{ ORDER( {[Demand Loan].Children}, [Product].[AlternateSort], DESC) }
TopCount and BottomCount
TopCount and BottomCountA classic Top 10 command:
{ TOPCOUNT( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, 10, [Test].([Posting Measures].[Amount]) )}
By omitting a sort order it sorts in the default order (which has the values descending in value and breaks any hierarchies present).
A Top 10 query with an explicit sort order for the results.
{ ORDER( {TOPCOUNT( {TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )},0)}, 10, [test].([Posting Measures].[Amount]))}, [test].([Posting Measures].[Amount]), BDESC) }
BDESC means to “break” the hierarchy.
Note how the chosen measure is repeated for the sort order. Although the same measure is used in the sample above you could actually find the top 10 products by sales but then display them in the order of, say, units sold or a ‘Strategic Importance’ attribute.
This is the top 10 products based on Test2's Rate values, not ordered so will be sorted according to the values in Test2.
{TOPCOUNT( {TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )},0)}, 10, [Test2].([Rate Measures].[Rate]))}
This is the top 10 products based on test2's data in the Rate measure, ordered from 10 through 1.
{ORDER( {TOPCOUNT( {TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )},0)}, 10, [test2].([Rate Measures].[Rate]))}, [test2].([Rate Measures].[Rate]), ASC)}
TopCount automatically does a descending sort by value to get the TOP members. If this is not desired, you might want to use the Head function (detailed below) instead.
BottomCount is the opposite of TopCount and so is used to find the members with the lowest values in a cube. Beware that the lowest value is often zero and if that value needs to be excluded from the query you will need to refer to the section on the Filter function later in this document.
A Bottom 10 query with an explicit sort order for the results.
{ ORDER( {BOTTOMCOUNT( {TM1FILTERBYLEVEL({TM1SUBSETALL( [Product] )},0)}, 10, [test].([Posting Measures].[Amount]))}, [test].([Posting Measures].[Amount]), BASC) }
Further reading: TopSum, TopPercent and their Bottom equivalents are useful related functions.
Filter, by values, strings and attributes
Filter, by values, strings and attributesThe FILTER function is used to filter the dimension based on some kind of data values rather than just the members and their hierarchy on their own. This data might be cube data (numeric or string) or attribute data. This requires a change of thinking from straightforward single dimensions (lists with a hierarchy and occasionally some attributes) to a multi-dimensional space, where every dimension in these cubes must be considered and dealt with.
This example returns the leaf members of Product that have an Amount value in the Test cube above zero.
{FILTER({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test].([Posting Measures].[Amount]) > 0 )}
Since the Test cube only has 2 dimensions – Product and Posting Measures this is a simplistic example. Most cubes will have more than just the dimension being filtered and the dimension with the filter value in. However, it is simple to extend the first example to work in a larger cube.
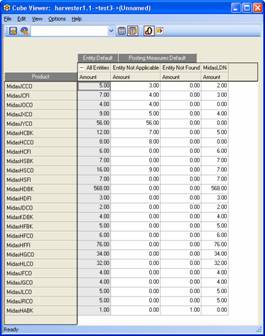
This example returns the leaf members of Product that have an Amount value for All Entities in the Test3 cube above zero.
{FILTER({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test3].([Entity].[All Entities],[Posting Measures].[Amount]) > 0 )}
As you can see from the above, simply include all the requisite dimension references inside the round brackets. Usually you will just need a specific named member (e.g. ‘All Entities’). If the dimension is omitted then the CurrentMember is used instead which is similar to using !dimension (i.e. “for each”) in a TM1 rule, and could return different results at a different speed.
Instead of just using a hardcoded value to filter against (zeroes in the examples above), this example returns all products with an amount in the Test cube greater than or equal to the value in the cell [MidasJCFI, Amount].
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test].([Posting Measures].[Amount]) >=
[Test].([Product].[MidasJCFI],[Posting Measures].[Amount])
)}
This query returns the products that have a Rate value in Test2 greater than MidasJXCO's Rate in Test2. Now, this query just returns a set of products – it’s up to you which cube you display these products in – i.e. you can run this while browsing Test and therefore return what looks like an almost random set of products but the fact is that the query is filtering the list of products based on data held in Test2. This may not immediately appear to be useful but actually it is, and can be extremely useful – for example display the current year’s sales for products that were last year’s worst performers. If the data for two years was held in different cubes then this would be exact same situation as this example. There are often many potential uses for displaying a filtered/focused set of data in Cube B that is actually filtered based on data in Cube A.
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test].([Posting Measures].[Amount]) >=
[Test2].([Product].[MidasJXCO],[Rate Measures].[Rate])
)}
As detailed elsewhere, Tail returns the final member(s) of a set. An example of when it is handy when used with Filter would be for finding the last day in a month where a certain product was sold. The simple example below initially filters Product to return only those with an All Entity Amount > 0, and then uses tail to return the final Product in that list.
{TAIL( FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test3].( [Entity].[All Entities], [Posting Measures].[Amount]) > 0
))}
Note: with the 'other' cubes having more dimensions than does Test the current member is used (‘each’), not 'All' so whether you want ‘each’ or ‘All’ you should write this explicitly to be clearer.
You can even filter a list in Cube1 where the filter is a value in one measure compared to another measure in Cube1. This example returns the Products with an amount in the Test cube above zero where this Amount is less than the value in Count.
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
(Test.[Posting Measures].[Amount] 0
)}
This example returns all the leaf products that have an Amount in Entity Not Applicable 10% greater than the Amount in Entity Not Found, in the Test3 cube. Not very useful but this was the only example cube we had to work with, but it would be very useful when comparing, say, Actual Q1 Sales with Budget, or finding out which cost centres’ Q2 Costs were 10% higher than Q1. Later in this document we will see how to take that 10% bit and make it a value from another cube, thus allowing administrators, or even end users, to set their own thresholds.
{FILTER(TM1FilterByLevel({TM1SUBSETALL( [Product] )}, 0),
test3.([Entity].[Entity Not Applicable], [Posting Measures].[Amount]) * 1.1 > test3.([Entity].[Entity Not Found], [Posting Measures].[Amount]))}
Filtering for strings uses the same method but you need to use double quotes to surround the string. For example, this query returns products that have a value of “bob” in the Test2 cube against the String1 member from the StringTest dimension. Note that TM1 is case-insensitive.
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test2].([StringTest].[String1]) = "bob"
)}
Filter functions can be nested if required, although the AND or INTERSECT functions may be useful alternatives.
The limit to the number of characters that an MDX subset definition can sometimes be, 256, is too restricting for many data-based queries. When trying to shoehorn a longer query into less characters there are a few emergency techniques that might help: consider whether you need things like TM1FILTERBYLEVEL, 0 (it might well be that the filter would only return members at the leaf level by definition anyway); whether the dimension name prefix can be removed if the member is guaranteed to be unique; remove all spaces; lookup cubes are not for end users so maybe you could shorten some names (cubes, dimension, members) drastically; whether there are alternative functions with shorter syntaxes that return the same result - e.g. an INTERSECT or AND versus a triple FILTER. Finally, if it really is vital to get a long query working then you can build up the final result in stages – i.e. put some of the filtering into Subset1, then use Subset1 as the subject of Subset2 which continues the filtering, etc.
Parent, Children, FirstChild, LastChild, Ancestors, Descendants, DrillDownLevel and TM1DrilldownMember
Parent, Children, FirstChild, LastChild, Ancestors, Descendants, DrillDownLevel and TM1DrilldownMemberChildren returns the set of members one level below a named parent.
{Product.[Demand Loan].Children}
FirstChild returns the… first child one level below a named parent.
{[Product].[Customer Lending].FirstChild}
Returns “Call Participation Purchased”.
LastChild returns the last child one level below a named parent. This is excellent for finding the last day in a month, since they can vary from 28 to 31. Another example is when a consolidation is set up to track a changing set of members (e.g. “Easter”, or “Strategic Customers”).
{[Product].[Customer Lending].LastChild}
Returns “Term Participation Purchased”.
Parent returns the first parent of a given member. If a member has more than one parent, and the full “unique path” to the member is not specified then the first parent according to the dimension order is returned.
{[Product].[MidasTPIS].Parent}
Returns “Bonds”.
{[Product].[External - Bonds].[MidasTPIS].Parent}
Would force TM1 to return the second parent, “External – Bonds”.
Descendants returns the named parent and all of its descendant children – i.e. the hierarchy down to the leaf level:
{Descendants(Product.[Customer Lending]) }
TM1DrilldownMember returns the same thing as descendants:
{TM1DRILLDOWNMEMBER( {[Product].[Customer Lending]}, ALL, RECURSIVE )}
DrillDownLevel just returns the parent and its immediate children:
{DRILLDOWNLEVEL( {[Product].[Customer Lending]})}
DrillDownLevel can be extended with a parameter to say which level to return the members from, rather than the level immediately below, but this doesn’t appear to work in TM1 v9.0 SP2 through to 9.1.1.36.
The common requirement to return a list of just leaf-level descendants of a given consolidated member just needs a level filter applied to the TM1DrillDownMember example above:
{TM1FILTERBYLEVEL({TM1DRILLDOWNMEMBER({[Product].[Customer Lending]},ALL,RECURSIVE)}, 0)}
Or:
{TM1FILTERBYLEVEL({DESCENDANTS(Product.[Customer Lending]) }, 0)}
Ancestors is like a more powerful version of Parent; it returns a set of all the parents of a member, recursively up though the hierarchy including any multiple parents, grandparents, etc.
{[Date].[2006-10-01].Ancestors}
Returns “2006 – October”, “2006 – Q4”, “2006 – H2”, “2006”, “All Dates”.
The Ancestor function returns a single member, either itself (,0) or its first parent (,1), first parent’s first parent (,2), etc. depending on the value given as a parameter.
{ancestor([Date].[2006-10-01], 0)}
Returns “2006-10-01”.
{ancestor([Date].[2006-10-01], 1)}
Returns “2006 – October”.
{ancestor([Date].[2006-10-01], 2)}
Returns “2006 – Q4”.
{ancestor([Date].[2006-10-01], 3)}
Returns “2006 – H2”.
{ancestor([Date].[2006-10-01], 4)}
Returns “2006”.
{ancestor([Date].[2006-10-01], 5)}
Returns “All Dates”.
Lag, Lead, NextMember, PrevMember, FirstSibling, LastSibling, Siblings and LastPeriods
Lag, Lead, NextMember, PrevMember, FirstSibling, LastSibling, Siblings and LastPeriodsLags and Leads are the equivalent of Dnext/Dprev.
{ [Date].[2006-10-03].Lead(1) }
will return 2006-10-04.
Lead(n) is the same as Lag(-n) so either function can be used in place of the other by using a negative value, but if only one direction will ever be needed in a given situation then you should use the correct one for understandability’s sake. Note that they only return a single member so to return the set of members between two members you can use the lastperiods function.
Equally you can use NextMember and PrevMember when you only need to move along by 1 element.
{ [Date].[2006-10-03].NextMember }
Or:
{ [Date].[2006-10-03].PrevMember }
To return the 6 months preceding, and including, a specific date:
{ LastPeriods(6, [Date].[2006-10-03]) }
Or:
LastPeriods(6, [Date].[2006-10-03])
Both of which work because LastPeriods is a function that returns a set, and TM1 always requires a set. Curly braces convert a result into a set which is why many TM1 subset definitions are wrapped in a pair of curly braces, but in this case they are not required.
This will return the rest (or the ones before) of a dimension's members at the same level, from a specified member. Despite its name LastPeriods works on any kind of dimension:
{ LastPeriods(-9999999, [Date].[2006-10-03]) }
Siblings are members who share a common parent. For example, a date of 14th March 2008 will have siblings of all the other dates in March the first of which is the 1st March and the last of which is 31st March. A cost centre under “West Coast Branches” would have a set of siblings of the other west coast branches.
The FirstSibling function returns the first member that shares a parent with the named member. For example:
{[Product].[MidasHCFI].FirstSibling}
Returns “MidasHCBK”.
While:
{[Product].[MidasHCFI].LastSibling}
Returns “MidasHSFI”.
The siblings function should return the whole set of siblings for a given member. TM1 9.0 SP2 through to 9.1.2.49 appear to give you the entire set of members at the same level (counting from the top down) rather than the set of siblings from FirstSibling through to LastSibling only.
{[Product].[MidasHCFI].Siblings}
Filtering by CurrentMember, NextMember, PrevMember, Ancestor and FirstSibling
Filtering by CurrentMember, NextMember, PrevMember, Ancestor and FirstSiblingThis example returns the members that have an Amount value in the Test cube above 18. The [Product].CurrentMember part is optional here but it makes the next example clearer.
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test].([Product].CurrentMember, [Posting Measures].[Amount]) > 18 )}
This query then modifies the previous query slightly to return members where the NEXT member in the dimension has a value above 18. In practice this is probably more useful in time dimensions.
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test].([Product].CurrentMember.NextMember, [Posting Measures].[Amount]) > 18 )}
This can then be improved to returning members where the next member is greater than their amount.
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
[Test].([Product].CurrentMember.NextMember, [Posting Measures].[Amount]) >
[Test].([Product].CurrentMember, [Posting Measures].[Amount]) )}
In addition to NextMember, PrevMember can also be used as could lags and leads.
The simple, but unsupported as of 9.1.1.89, Name function allows you to filter according to the name of the member. As well as exact matches you could find exceptions, ‘less-thans’ and ‘greater-thans’, bearing in mind these are alphanumeric comparisons not data values.
This example returns all base members before and including the last day in January 1972.
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL([Date])} ,0)},
[Date].CurrentMember.Name
For example, this could be a useful query even a dimension not as obviously sorted as dates are:
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL([Product])} ,0)},
[Product].CurrentMember.Name
which returns all base members before MidasJ in terms of their name rather than their dimension index.
Parent returns the first parent of a given member:
{ [Product].[Customer Lending].Parent }
Used with Filter you can come up with another way of doing a “children of” query:
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL([Date])} ,0)},
[Date].CurrentMember.Parent.Name = "1972 - January")}
Ancestor() can be used instead of Parent if desired. This example returns base-level product members whose first parents have a value above zero, in other words a kind of family-based suppress zeroes: a particular product might have a value of zero but if one if its siblings has a value then it will still be returned.
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].(Ancestor([Product].CurrentMember,0), [Posting Measures].[Amount]) > 0 )}
This example filters the products based on whether they match the Amount value of MidasHCBK.
{FILTER(
{TM1SUBSETALL( [Product] )}, [Test].(Ancestor([Product].CurrentMember,0), [Posting Measures].[Amount]) = [Test].([Product].[MidasHCBK], [Posting Measures].[Amount])
)}
This example uses FirstSibling to filter the list based on whether a product’s value does not match that products’ First Sibling (useful for reporting changing stock levels or employee counts over time, for example, things that are usually consistent).
{FILTER( {TM1FilterByLevel({TM1SUBSETALL( [Product] )}, 0)}, [Test].(Ancestor([Product].CurrentMember,0), [Posting Measures].[Amount]) <> [Test].([Product].CurrentMember.FirstSibling, [Posting Measures].[Amount]) )}
Filtering by Attributes and logical operators
Filtering by Attributes and logical operatorsThis returns members that match a certain attribute value using the Filter function.
{FILTER( {TM1SUBSETALL( [Product] )}, [Product].[Category] = "Customer Lending")}
This example looks at multiple attribute values to return a filtered list:
{
FILTER(
{TM1SUBSETALL( [Product] )},
(
([Product].[Category]="Customer Lending" OR [Product].[Type]="Debit")
AND
([Product].[Internal Deal]<>"No")
)
)
}
Filtering by level, attribute and pattern are combined in the following example:
{TM1FILTERBYPATTERN( {FILTER( TM1FILTERBYLEVEL({TM1SubsetAl([Product])},0),
[Product].[Internal Deal] = "Yes")}, "*ID??") }
Head, Tail and Subsetw
Head, Tail and SubsetwWhere TopCount and BottomCount sort the values automatically and chop the list to leave only the most extreme values, Head combined with Filter works in a similar manner but Head then returns the FIRST members of the filtered set in their original dimension order.
These queries simply return the first and last members of the Product dimension as listed when you hit the ‘All’ button:
{Head ( TM1SubsetAll ( [Product] ) )}
{Tail ( TM1SubsetAll ( [Product] ) )}
This returns the actual last member of the whole Product dimension according to its dimix:
{Tail(TM1SORTBYINDEX( {TM1DRILLDOWNMEMBER( {TM1SUBSETALL( [Product] )}, ALL, RECURSIVE )}, ASC))}
An example of Tail returning the last member of the Customer Lending hierarchy:
{Tail(TM1DRILLDOWNMEMBER( {[Product].[Customer Lending]}, ALL, RECURSIVE ))}
An example of Head returning the first 10 members (according to the dimension order) in the product dimension that have an Amount in the Test cube above zero.
{HEAD( FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) > 0 ), 10)}
With both Head and Tail the “,10” part can actually be omitted (or just use “,0”) which will then return the first or last member.
This returns the last (in terms of dimension order, not sorted values) product that had an amount > 0 in the Test cube.
{TAIL( FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) > 0 ))}
One example of when this is useful over TopCount or BottomCount – i.e. when sorting the results would be detrimental - would be to return the last day the year when a certain product was sold.
Subset is closely related to Head and Tail, and can actually replicate their results, but is additionally capable of specifying a start point and a range, similar in concept to substring functions (e.g. SUBST) found in other languages, though working on a tuple of objects not strings.
The equivalent of Head, 10 would be:
{Subset ( {Tm1FilterByLevel(TM1SubsetAll ( [Product] ) , 0)}, 1, 10)}
But Subset would also allow us to start partitioning the list at a point other than the start. So for example to bring in the 11th – 20th member:
{Subset ( {TM1FilterByLevel(TM1SubsetAll ( [Product] ) , 0)}, 11, 10)}
Note that asking for more members than exist in the original set will just return as many members as it can rather than an error message.
Union
UnionUnion joins two sets together, returning the members of each set, optionally retaining or dropping duplicates (default is to drop).
This creates a single list of the top 5 and worst 5 products.
{UNION(
TOPCOUNT( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, 5, [Test].([Posting Measures].[Amount]) ),
BOTTOMCOUNT( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, 5, [Test].([Posting Measures].[Amount]) )
)}
To create a list of products that sold something both in this cube and in another (e.g. last year and this):
{UNION(
FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) > 0 ) ,
FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test3].([Posting Measures].[Amount], [Entity].[All Entities]) > 0 )
) }
Intersect
IntersectIntersect returns only members that appear in both of two sets. One example might be to show products that performed well both last year and this year, or customers that are both high volume and high margin. The default is to drop duplicates although “, ALL” can be added if these are required.
This example returns leaf Product members that have an Amount > 5 as well as a Count > 5.
{
INTERSECT(
FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) > 5 ) ,
FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Count]) > 5 )
)
}
Except and Validating Dimension Hierarchies
Except and Validating Dimension HierarchiesThe function takes two sets as its mandatory parameters and removes those members in the first set that also exist in the second. In other words it returns only those members that are not in common between the two sets, but note that members that are unique to the second set are not included in the result set.
Except is a useful function in a variety of situations, for example when selecting all the top selling products except for 1 or 2 you already know are uninteresting or irrelevant, or selecting all the cost centres with high IT costs – except for the IT department.
The simplest example is to have a first set of 2 members and a second set of 1 of those members:
EXCEPT (
{ [Product].[MidasJCCO],[Product].[MidasJCFI] },
{ [Product].[MidasJCCO] }
)
Which returns MidasJCFI, the only member not in common between the two sets.
For the purposes of maximum clarity in the rest of this section only, we will drop the [Product] reference and trust that these product names are uniquely in the Product dimension on our server.
This query returns nothing:
EXCEPT({ [Product].[MidasJCCO],[Product].[MidasJCCO] },{ [Product].[MidasJCCO] })
This example returns all Products, except for MidasJCCO and the Demand Loan family.
{ EXCEPT(
{ TM1SUBSETALL( [Product] )},
{ [MidasJCCO], Descendants([Demand Loan]) }
)}
The optional extra ALL parameter allows duplicates to remain prior to the determination of the difference; i.e. matching duplicates within the first set are discarded, while non-matching duplicates are retained.
A simple example where there are duplicate members in the first set:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI] },
{ [MidasJCFI] }
)
Returns MidasJCCO (because duplicates are discarded without ALL), while:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI] },
{ [MidasJCFI] }
, ALL)
Returns MidasJCCO, MidasJCCO (as ALL allows the duplicate MidasJCCO members to be retained).
Note that ALL has no effect on the following query as MidasJCFI is the only member not in common between the two sets and so this is the only result either way:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI] },
{ [MidasJCCO] }
)
Returns MidasJCFI.
Remember, the members in the first set that also exist in the second are eliminated, hence (both instances of) MidasJCCO is eliminated
So if you were to ask for EXCEPT({Apples, Apples, Oranges, Oranges}, {Apples, Pears}) then the final set would be{Oranges} without ALL and {Oranges, Oranges} with ALL. Because matching duplicates in the first set are eliminated first (that is, duplicates in the first set that match a member in the second set), Apples (the only member in the second set that matches a pair of duplicates in the first set, is eliminated.
To put the fruit down and return to our demo model we can write the equivalent query against products:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI],[MidasJCFI] },
{ [MidasJCCO],[MidasHDBK] }
)
Returns just one MidasJCFI (the equivalent of Oranges above) while:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI],[MidasJCFI] },
{ [MidasJCCO],[MidasHDBK] }
, ALL)
Returns two instances of MidasJCFI.
These results are due to the fact that, in the example with ALL, MidasJCCO is eliminated due to a matching member in set 2, while MidasJCFI is reduced to 1 instance due to the lack of ALL. MidasHDBK has no impact because it could not be subtracted from set 1 as it was not in set 1. When ALL was used in the second example, the two MidasJCCO members were still eliminated due to a match in set 2, and MidasHDBK was still irrelevant, but this time the two MidasJCFI members were left alone due to the ALL allowing duplicates.
A final example, similar to the last but slightly expanded:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI],[MidasJCFI] },
{ [MidasHCBK],[MidasHDBK] }
)
Returns MidasJCCO, MidasJCFI; while:
EXCEPT (
{ [MidasJCCO],[MidasJCCO],[MidasJCFI],[MidasJCFI] },
{ [MidasHCBK],[MidasHDBK]}
,ALL)
Returns MidasJCCO, MidasJCCO, MidasJCFI, MidasJCFI.
Note: the following section does not work in v9.1 SP2, but does work in v9.0. Your mileage may vary.
A particularly clever use of Except is to check a TM1 dimension for a valid structure. A simple query can return a list of members that do not eventually roll up into a particular consolidated member. This could be included in a TI process to automate the consistency checking of dimensions after an update.
This example returns all the members in the dimension that do not roll up into All Products:
EXCEPT (
TM1SUBSETALL( [Product] ),
TM1DRILLDOWNMEMBER( {[Product].[All Products]}, ALL, RECURSIVE ))
Modifying this slightly makes it return base-level members that do not roll up into All Products:
EXCEPT (
TM1FILTERBYLEVEL(TM1SUBSETALL( [Product] ), 0),
TM1FILTERBYLEVEL(TM1DRILLDOWNMEMBER( {[Product].[All Products]}, ALL, RECURSIVE ), 0))
This query returns members that have been consolidated twice or more at some point under the given consolidated member – this will often mean there has been an accidental double-count.
EXCEPT (
TM1DRILLDOWNMEMBER( {[Product].[All Products]}, ALL, RECURSIVE ),
TM1SUBSETALL( [Product] ), ALL)
It will return one instance of the multi-consolidated member for each time it is consolidated greater than once – i.e. if it has been consolidated 4 times then it will return 3 instances.
This is due to the fact that TM1SUBSETALL( [Product] ) will only return one instance of a member that has been consolidated multiple times while the TM1DrilldownMember function will return all the instances. You are reminded that [Dimension].[Member] is actually a shortcut that usually works in TM1 but because the MDX specification allows for member names to be non-unique within a dimension the full address of a member is actually [Dimension].[Parent1].[Parent2]…[Member]. Therefore more specific references to duplicate members may be needed, for example [Product].[Demand Loan].[MidasHCBK] will address a different instance of MidasHCBK than would [Product].[Discount Loan].[MidasHCBK]. In this case, with the Except function, they are treated as if they are different member names altogether.
ToggleDrillState
ToggleDrillStateToggleDrillState changes the default drill state from a returned set – so if the first query returns a member in a hierarchy rolled up then it will drill it down, or vice versa.
For example,
{[Product].[Customer Lending].Children}
Returns:
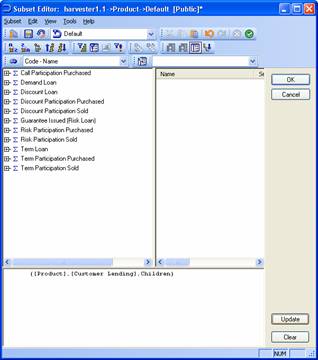
Whereas this query:
{TOGGLEDRILLSTATE( {[Product].[Customer Lending].Children},{[Product].[Demand Loan]} )}
Returns:
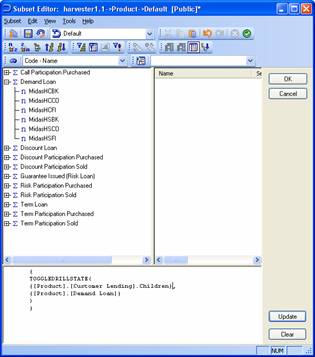
Using TM1 Subsets, TM1Member and TM1SubsetToSet
Using TM1 Subsets, TM1Member and TM1SubsetToSetOne of the special features of using MDX with TM1 dimensions is that existing subsets can be used within the query for defining a new subset. This can be useful in allowing a simpler ‘building block’ approach and for not having to repeat the same code over and over again – and having to maintain it.
Used throughout this section, [Report Date] is an existing subset in the Date dimension containing one leaf date member and [test2] is an existing 20-member subset.
Note that private subsets are used in preference to public subsets when there is one of each with the same name. This can allow a public subset to return different results based on the contents of different users’ private subsets, though inevitably with some issues with reliability of results.
To simply return the member(s) of pre-existing Date subsets:
[Date].[Report Date]
Or
TM1SubsetToSet([Date], "Report Date")
The first syntax may be shorter and more convenient but bear in mind, as per the TM1 help file, “Since the same syntax ( .IDENTIFIER ) is used for members and levels, a subset with the same name of a member or a level will never be instantiated.” The second syntax on the other hand will happily work with any subset names even if they are named the same as a cube or dimension.
To return the first member of the test2 subset:
{ [Date].[test2].Item(0) }
To return a valid cube reference within a more complex query:
TM1Member([Date].[Current Date].Item(0), 0)
For example:
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Account] )}, 1)}, [Reconciliation].([Entity].[All Entities],TM1Member([Date].[Current Date].Item(0),0),[Reconciliation Measures].[Transaction Balance]) <> 0 )}
To start with the fourth item (.Item counts from zero) in the test2 subset and then return the preceding 14 members from the whole dimension, including the fourth item:
{ lastperiods(14, tm1member( [Date].[test2].item(3),0) )}
This example returns the one date in Report Date and the next 13 periods, sorted with the earliest date first – a moving 2-week reporting window which just needs the Report Date subset to be maintained.
{ tm1sort( lastperiods(-14, TM1Member( [Date].[Report Date].Item(0), 0) ), ASC)}
And this example does a similar thing working in the other direction:
{ tm1sort( lastperiods(14, TM1Member( [Date].[Report Date].Item(0), 0) ), DESC)}
This query uses another subset, Strategic Products, as a building block and finds the Top 5 members within it, even though this ranking may well have been based on different values than the original subset was built on. For example, a subset that is already defined may list the 10 highest spending customer segments in terms of year to date actuals, and you then build a new subset that works with these 10 only to find the top 5 in terms of planned marketing spend next quarter.
{ ORDER( {TOPCOUNT( {[Product].[Strategic Products]}, 5, [Test].([Posting Measures].[Count]))}, [Test].([Posting Measures].[Count]), BDESC) }
Here’s a bigger example using TM1member and TM1SubsetToSet functions, in addition to various others. It takes the single period in the “Current Date” subset and returns the last day of the two preceding months. There would be several different ways of achieving the same result.
{
union(
{tail(descendants(head(lastperiods(3,ancestor(
tm1member(tm1subsettoset([Date], "Current Date").item(0),0),1)
))))},
{tail(descendants(head(lastperiods(2,ancestor(
tm1member(tm1subsettoset([Date], "Current Date").item(0),0),1)
))))}
)
}
Username and StrToMember
Username and StrToMemberIt returns the TM1 username (or Windows domain username depending on the security system being used – for example, “GER\JEREMY”) of the user who runs the query. Note that you may need to give all users Read access to the }Clients dimension and all its elements.
It is not documented in the help file as being officially supported by TM1 but it is a standard MDX feature that appears to work in v8.3. However, since 8.4.3 until 9.1.2.49 it is reported as failing to automatically update when a new user uses the subset. This can be circumvented by running a frequent TI process that uses the subset as its datasource and the following line in Prolog (Workaround reported by Steve Vincent on the Applix Forum, 2nd August 2006):
DIMENSIONSORTORDER('}CLIENTS','BYNAME','ASCENDING','','');
With this “micro-process” workaround set to run every few minutes a pseudo-dynamic result is possible. An actual solution to the problem should be tested for in your version if it is 9.1 or later.
To save a dynamic subset it needs to be set up on the }Clients dimension – choose View / Control Objects in Server Explorer to see this dimension. Once you have saved the public subset (e.g. as “Current User”) you can turn this option off again.
{TM1FILTERBYPATTERN( {TM1SUBSETALL( [}Clients] )}, USERNAME )}
As an alternative to the above method, and as a way of including the current username directly in queries use the StrToMember function which converts a plain string into a valid MDX member reference.
{StrToMember("[}Clients].["+USERNAME+"]") }
Either way the subset can then be referred to on Excel spreadsheets, VBA processes and, as it is simply a standard TM1 subset, in TM1 Websheets.
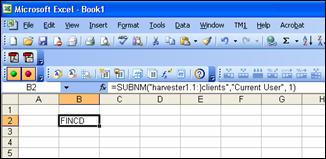
As a non-MDX alternative v9.1.2.49 introduced a =TM1User(servername) worksheet function which could be used in some circumstances.
Data-based queries, Filter, Sum, Avg and Stdev
Data-based queries, Filter, Sum, Avg and StdevSometimes it is not adequate to simply use a single value in a query; you need to consider a combination of values. It might be that this combination is only needed for one or two queries, though, so it is not desirable to calculate and store the result in the cube for all to see. Therefore it is more logical to quickly calculate the result on the fly and although this is then repeated every time the subset is used, it is still the preferred choice. The function Sum, Avg and Stdev are therefore useful for things that are only needed occasionally or by a limited number of users and means that the actual cube is thus smaller and more efficient.
SUM, as it might appear, sums up a set of numbers. This allow the aggregation of members not already consolidated in the model. This example checks the Test3 cube for products whose Amounts in the on-the-fly-consolidation of 2 entities are greater than 50.
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
SUM(
{[Entity].[MidasLDN], [Entity].[Entity Not Applicable]},
Test3.([Posting Measures].[Amount]) ) > 50
)}
AVG calculates the average value of a set. Note how empty (zero) cells are not included by the AVG function so the resulting average value might be higher than you expected.
This example returns a list of leaf products that have an Amount value in the Test cube higher than the average Amount value of all leaf products (or rather all non-zero leaf products).
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
(Test.[Posting Measures].[Amount] >
AVG({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]))
)
)}
The set of members that AVG works on here (AVG{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}) can be changed to something that doesn’t match the list of members being filtered earlier in the query. For example, return a list of all leaf products that are higher than the average of the leaf descendants of the Customer Lending consolidation only.
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
(Test.[Posting Measures].[Amount] >
AVG({DESCENDANTS(Product.[Customer Lending]) },[Test].([Posting Measures].[Amount])))
)}
STDEV is the standard deviation function. It returns the average distance from each value in a set to the average of the set as a whole. In this way you can calculate how consistent or unpredictable a set of data is – if all the values lie tightly around the average, or if the values vary to be extremely high and low.
This example returns the outlying products whose Amount value in the Test cube is greater than the average value plus the standard deviation – i.e. those products who have values that are “above averagely above the average”.
{FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
(
Test.[Posting Measures].[Amount] >
(
AVG({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]))
+
STDEV( {FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) > 0 )}
)
)
)
)}
Note that the AVG function automatically drops empty cells from the filtering set but STDEV does not so we have to apply our own filter.
The equivalent lower-bound outlier query would be:
{FILTER(
{FILTER( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) > 0 )},
(
Test.[Posting Measures].[Amount] 0 )}
)
)
)
)}
The above queries could be INTERSECTed for both sets of outliers in one subset, if required.
Further reading: The MEDIAN function is also supported by TM1 and might be more appropriate than AVG (mean) in some circumstances.
Using parameters in queries
Using parameters in queriesTM1Member will allow you to use parameterized references by using cube values as part of the query itself. For example if a UserParams cube was created with the }Clients dimension (thus allowing concurrent usage by all users) which would hold various choices made by users as they used your application, then dynamic subsets could use those choices as part of their syntax, thus altering not just the thresholds for comparisons (we can see elsewhere in this document how to check if something is, say, above a certain threshold which is actually a value in another cube) but the actual thing that is queried in the first place.
For example, this shows the descendants of a parent member, the name of which is held in the 2D UserParams cube at the intersection of the current username and ‘SelectedParentDimix’.
{DESCENDANTS(TM1Member(
TM1SUBSETALL( [Product] ).Item([UserParams].(StrToMember("[}Clients].["+USERNAME+"]"), [UserParamMeasures].[SelectedParentDimix])-1)
, 0)) }
Below are screenshots showing the parameter cube which can be extended to hold various user-specific selections and then link them into dynamic subsets plus the other relevant screens.
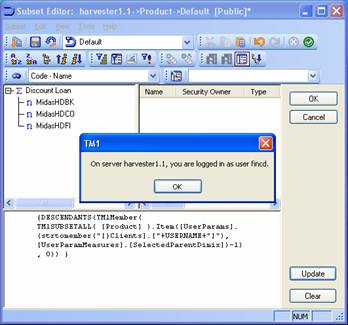
Generate
GenerateThe Generate function applies a second set to each member of a first set, performing a union of the results. Duplicates are dropped by default but can be retained with “,ALL”.
Although Generate doesn’t really do anything unique in itself it is a very useful way of shortening what would otherwise be long, laborious and error-prone queries.
In the following example the top performing child product is returned for each member of Level 1 of the hierarchy:
{Filter(
GENERATE(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 1)},
TopCount(Descendants([Product].CurrentMember, 1),1,Test.([Posting Measures].[Amount])))
,Test.([Posting Measures].[Amount]) > 0
)}
Count and IIF
Count and IIFCaveat: Note that IIF is not listed in the TM1 v9.0 SP2 help file as being supported so use at your own risk.
Count returns the number of items in a set but this set can be a set of members or a set of data values. The result is, obviously, a number and is often returned in reports when used in MDX queries outside of TM1. When trying to use it do define a TM1 subset it can only be used as part of the query logic and not as a result itself.
Count can be wrapped around a lot of the other MDX functions and so can be used in many different scenarios. One example is to count how many children a month has and, if there are 28, doing something that is unique to February. Although dimension subsets are usually a list of meaningful items in a business model and are included within application cubes, it is actually possible to have dimensions for administrator purposes only (that are never used to build cubes) which might indicate the state of something – e.g. “All Passwords Set”, or “Reconciliation Failed” and the Count function could be used to define a subset that contains one of these members, which is information for the administrator only.
IIF allows you to introduce some branching logic in your queries – i.e. do one thing if this is true, otherwise do something else. You could use it to apply different statistical functions to members that have certain attributes. It works quite commonly with Count to allow one thing to happen if the count of something falls below a threshold, or do something else if not.
This example performs either a Top 5 or a Top 10 on all base products’ Amounts in the Test cube, depending on whether the number of base level Products is 10 or less at the time the query is run.
{ TOPCOUNT( {TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
IIF(Count({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}) <= 10, 5, 10),
[Test].([Posting Measures].[Amount]) )}
This example does a TopCount of the base products based on their Amount value in the Test cube where the number of items displayed is equal to the number of cells in the Test cube whose Amount value is anything other than zero.
{TOPCOUNT(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
Count(
Filter({TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)}, [Test].([Posting Measures].[Amount]) <> 0),
)
)
}
These are fairly pointless examples, practically speaking, but they show the syntax.
Comments
CommentsComments allow you to explain, to yourself and/or to your users, what the query is trying to achieve, how it works, who wrote it or amended, etc.
Use "//" or "—" (without the double quotes) to end a line with a comment or to have the comment on its own line.
You can also use “/* COMMENT */” (again without the quotes) to insert a comment in the middle of a
line. You are also able to type anything after the command.
This heavily-commented example returns all the products beginning “MidasJ”:
//Comment number 1
/* this is another comment */
{TM1FILTERBYPATTERN( //and another comment
-- and another comment
{TM1SUBSETALL( [Product] )},/* this is yet another comment */ "MidasJ*")}
You seem to be able to type what you like here, but treat with caution
This does not work in version 8.2.7 but does in at least 9.0 and 9.1.1.
The fallacy of blb files
The fallacy of blb filesTM1 system files with the blb extension, incorrectly referenced as "cube formatting" files (admin guide p.35) are actually "rule formatting" files for the "standard" rules editor (prior to 9.1).
The rules editor actually displays the contents of the .blb if there is one, otherwise it defaults to the .rux.
Unfortunately things can go wrong, and the .blb file gets desynchronised from the actual .rux or just go blank.
As a result, what you see in the rule editor are NOT the rules attached to your cube and it becomes tricky to pinpoint any issue as the rule tracer gets confused too.
A simple fix is to delete the associated .blb file in the TM1 Data folder and reopen the rules in the rule editor. Well it works only until the next time it goes desynchronised or blank.
From 9.1, you can turn on the new rules editor from the tm1s.cfg:
AdvancedRulesEditor = T
Ultimately if you really cannot do without formatting, consider using an editor with highlighting features and copy/paste the rules.
Turbo Integrator highlighters
Turbo Integrator highlightersTo make your TM1 developer day more colorful, how about a syntax highlighter for Turbo Integrator? or 2?
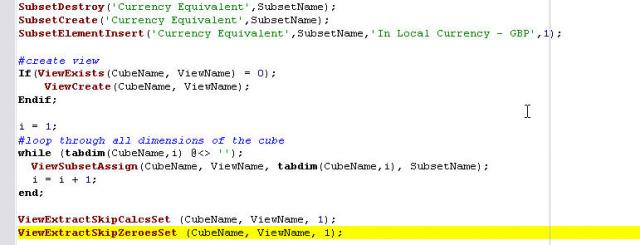
TM1 Highlighter for PSPad
Following up on that, I generated a syntax highlighter for PSPad which I usually use for scripting.
- Download the file TM1.ini, then in PSPad:
- Settings->User Highlighter
- Load
- Settings->Highlighter Settings
- Select TM1 and OK
TM1 Highlighter for UltraEdit
-
Download tm1-ultraedit.txt
-
In UltraEdit, Advanced->Configuration->Editor Display->Syntax Highlighting, open WORDFILE.TXT
-
Copy/paste the contents of tm1-ultraedit.txt in your wordfile.txt
-
Click OK. Enjoy.
VBA
VBAVBA snippets of code to integrate with Perspectives
Removing TM1 formulas from Excel sheets
Removing TM1 formulas from Excel sheetsThe following code adds a button in your Excel toolbars to replace all TM1 formulas in the current book with their values in order to get your worksheets TM1-free.
It has the following features:
- toolbar/button for ease of use
- applies to all sheets in the workbook
- changes all TM1 DB functions (DBRW, DBR, DBA...) and SUBNM/VIEW into values
This code might get included in a future version of the TM1 Open Source Toolkit
/!\ Mind that dynamic spreadsheets will regenerate all the DBRW formulas in the section boundary on a reload unless you remove all the stored names.
A quick equivalent hack is to simply drop the "paste values" icon next to the copy icon in the standard Excel toolbar. So when you need to remove formulas, click top left corner of the sheet and copy + paste values buttons. It does the job just as fast.
-----MODULE1--------------
Function bCommandBarExists(sCmdBarName As String) As Boolean
'test if a given menu exists
Dim bCbExists As Boolean
Dim cb As CommandBar
bCbExists = False
For Each cb In Application.CommandBars
If cb.name = sCmdBarName Then
bCbExists = True
Exit For
End If
Next
bCommandBarExists = bCbExists
End Function
Sub addMenu()
'add "freeze values" entry in TM1 menu
Dim cmdbar As CommandBar
Dim toolsMenu As CommandBarControl
Dim myMenu As CommandBarPopup
Dim subMenu As CommandBarControl
' Point to the Worksheet Menu Bar
Set cmdbar = Application.CommandBars("Worksheet Menu Bar")
' Point to the Tools menu on the menu bar
Set toolsMenu = cmdbar.Controls("TM1")
' Create the sub Menu(s)
Set subMenu = toolsMenu.Controls.Add
With subMenu
.Caption = "Freeze values"
.BeginGroup = True
.OnAction = "'" & ThisWorkbook.name & "'!DeleteTM1Formulas" ' Assign Macro to Menu Item
End With
End Sub
Sub BuildCustomToolbar()
'build a new TM1 toolbar for "freeze values"
Dim oCmdBar As CommandBar
On Error Resume Next
'point to custom toolbar
Set oCmdBar = CommandBars("TM1 Freeze")
'if it doesn't exist create it
If Err <> 0 Then
Set oCmdBar = CommandBars.Add("TM1 Freeze")
Err = 0
With oCmdBar
'now add a control
With .Controls.Add(msoControlButton)
.Caption = "Freeze Values"
.OnAction = "!DeleteTM1Formulas"
.Tag = .Caption
'set the button icon
.FaceId = 107
End With
End With
End If
'make it visible
oCmdBar.Visible = True
'on top
Application.CommandBars("TM1 Freeze").Position = msoBarTop
End Sub
Sub DeleteTM1Formulas()
'replace TM1 formulas with their current values
Dim ws As Worksheet, AWS As String, ConfirmReplace As Boolean
Dim i As Integer, OK As Boolean
If ActiveWorkbook Is Nothing Then Exit Sub
i = MsgBox("Replace all TM1 formulas with their current values?", _
vbQuestion + vbYesNo)
ConfirmReplace = False
If i = vbNo Then Exit Sub
ConfirmReplace = False
AWS = ActiveSheet.name
Application.ScreenUpdating = False
For Each ws In ActiveWorkbook.Worksheets
OK = DeleteLinksInWS(ConfirmReplace, ws)
If Not OK Then Exit For
Next ws
Set ws = Nothing
Sheets(AWS).Select
Application.ScreenUpdating = True
End Sub
Private Function DeleteLinksInWS(ConfirmReplace As Boolean, _
ws As Worksheet) As Boolean
'replace formulas with their values
Dim cl As Range, cFormula As String, i As Integer
DeleteLinksInWS = True
If ws Is Nothing Then Exit Function
Application.StatusBar = "Deleting external formula references in " & _
ws.name & "..."
ws.Activate
For Each cl In ws.UsedRange
cFormula = cl.Formula
If Len(cFormula) > 0 Then
If Left$(cFormula, 5) = "=SUBN" Or Left$(cFormula, 3) = "=DB" Or Left$(cFormula, 5) = "=VIEW" Then
If Not ConfirmReplace Then
cl.Formula = cl.Value
Else
Application.ScreenUpdating = True
cl.Select
i = MsgBox("Replace the formula with the value?", _
vbQuestion + vbYesNoCancel, _
"Replace external formula reference in " & _
cl.Address(False, False, xlA1) & _
" with the cell value?")
Application.ScreenUpdating = False
If i = vbCancel Then
DeleteLinksInWS = False
Exit Function
End If
If i = vbYes Then
On Error Resume Next
' in case the worksheet is protected
cl.Formula = cl.Value
On Error GoTo 0
End If
End If
End If
End If
Next cl
Set cl = Nothing
Application.StatusBar = False
End Function
TM1 SDK
TM1 SDKAttached below is the TM1 Open Source Toolkit developed by James Wakefield
v 1.0.1 adds:
- vba code for running TI processes/chores
- vba for running MDX reports
v 1.0 includes:
- Treeview control on form showing TM1 Servers with cubes and public views. An Imagelist control is used to populate the treeview with images.
- Button on Treeview form allowing user to select view and be written to Excel
- Button on Treeview form allowing user to select view and be shown equivalent MDX statement
- Button on Treeview form allowing user to select view and be shown equivalent XML statement
- form in vba that people can easily use to collect text commentary into TM1
- KillTM1 module of Robert Gardiner's that kills DBRW'S
TM1 and Excel in one click
TM1 and Excel in one clickThe following code will:
- load TM1 add-in
- hide the TM1 toolbars (most people do not need spreading, developer.. tools)
- log you on your TM1 server
- open the Server Explorer
- expand the applications and cubes
so you are just 1 click away from accessing your TM1 data :)
Replace the "\\path\to\tm1p.xla","server","user" and "password" strings to your own settings.
----THIS WORKBOOK------------------
Private Sub workbook_open()
'load TM1 add-in if the TM1 menu do not exist
If Not (bCommandBarExists("TM&1")) Then
Workbooks.Open ("\\path\to\tm1p.xla")
End If
'hide TM1 toolbars
On Error Resume Next
With Application
.CommandBars("TM1 Servers").Visible = False
.CommandBars("TM1 Developer").Visible = False
.CommandBars("TM1 Spreading").Visible = False
.CommandBars("TM1 Standard").Visible = False
End With
On Error GoTo 0
msg = Run("n_connect", "server", "user", "password")
If msg <> "" Then
MsgBox msg
End If
Application.Run "TM1RECALC"
End Sub
-----MODULE 1----------------------
Function bCommandBarExists(sCmdBarName As String) As Boolean
Dim bCbExists As Boolean
Dim cb As CommandBar
bCbExists = False
For Each cb In Application.CommandBars
If cb.name = sCmdBarName Then
bCbExists = True
Exit For
End If
Next
bCommandBarExists = bCbExists
End Function
Sub Open_SE()
Application.Run "TM1StartOrionWithAutomation"
'wait for Server Explorer to open
Application.Wait Now + TimeValue("00:00:05")
'expand Applications
SendKeys "{RIGHT}{RIGHT}{RIGHT}{RIGHT}{RIGHT}"
'jump to cubes and expand
SendKeys "{C}{RIGHT}"
End Sub
VBA misc
VBA miscVBA function to check if a user is already logged in
Function IsUserLoggedIn(UserName As String, _
Servername As String) As Variant
IsUserLoggedIn = _
Application.Run("DBRW", Servername & "}ClientProperties" _
, UserName, "STATUS")
End Function
You can then use that in a sub as shown below:
Sub CheckWhetherUserIsLoggedIn()
If IsUserLoggedIn("MyUser", "TM1:") = "ACTIVE" Then
MsgBox "User is logged into TM1."
Else
MsgBox "User is doing something more interesting."
End If
End Sub
Disabling the DEL key to forbid users from deleting DBRW formulas
----THISWORKBOOK (Code) ----------
Private Sub Workbook_Activate()
DisableDel
End Sub
Private Sub Workbook_Deactivate()
EnableDel
End Sub
Private Sub Workbook_BeforeClose(Cancel As Boolean)
a = MsgBox("Your data have already been saved in Tm1, you don't need to save this Excel slice", vbInformation)
EnableDel
ActiveWorkbook.Close False
End Sub
--------- MODULE1 (CODE) --------------
Sub DisableDel()
Application.OnKey "{DEL}", "SendSpace"
'MsgBox "Delete Key Disable"
End Sub
Sub EnableDel()
Application.OnKey "{DEL}"
'MsgBox "Delete Key Enable"
End Sub
Sub SendSpace()
'MsgBox "Delete key not allowed. Sending a space instead"
SendKeys " ~"
End Sub
Undocumented TM1 macros
TM1RECALC1 : same as shift-F9, refreshes only the active worksheet
TM1RECALC : same as F9, refreshes ALL open workbooks
TM1REFRESH : same as Alt F9, rebuilds (dynamic spreadsheets) and refreshes ALL open workbooks
TM1StartOrionWithAutomation : opens Server Explorer
CUBES_BROWSE : opens Server Explorer
SUBDELETE: deletes a subset (if unused) ex: Application.Run("SUBDELETE", "myserver:account", "MySubset")
TM1InsertViewControl : starts In Spreadsheet browser
TWHELP : opens TM1 perspectives help
TWDEFAULTS : opens TM1 Options menu
TWMERUL : opens rules worksheets menu
TWMEDIM : opens dimensions worksheets menu
to be continued...
Excel formulas references
When editing a cell formula (F2), you can easily toggle between relative and absolute references with the F4 key: $B$10 -[F4]-> B$10 -[F4]-> $B10 -[F4]-> B10
Zero out portions
Zero out portionsIn order to zero out data points you can do it either:
- from Cube Viewer
select all the cells with the pointer
right click: Data Spread->Clear...
or
select the top left corner cell of the portion to zero out
right click: Data Spread->Repeat
set value box to 0 and tick boxes Extend "right" and "down"
- from a TI process
in the Prolog tab:
ViewZeroOut('Cube','View');
setup the 'View' to zero out then run that process
Admins
Adminssection dedicated to material for admins
Backup
BackupBefore running the following script you need to setup a chore with a TI process to execute that line in Prolog:
SaveDataAll;
/!\ Avoid using the SaveTime setting in tm1s.cfg as it could conflict with other chores/processes trying to run at the same time
here is the DOS backup script that you can schedule to backup your TM1 server
netsvc /stop \\TM1server "TM1 service" sleep 300 rmdir "\\computer2\path\to\backup" /S /Q mkdir "\\computer2\path\to\backup" xcopy "\\TM1server\path\to\server" "\\computer2\path\to\backup" /Y /R /S xcopy "\\TM1server\path\to\server\}*" "\\computer2\path\to\backup" /Y /R /S netsvc /start \\TM1server "TM1 service"
Beware of Performance Monitor defaults spamming transaction log
Beware of Performance Monitor defaults spamming transaction logThe Performance Monitor in TM1 is a great tool to gather helpful statistics about your system and pinpoint all sorts of bottlenecks.
You can start the Performance Monitor in 2 ways:
- In Server Explorer -> Server -> Start Performance Monitor
- add PerformanceMonitorOn=T in tm1s.cfg, this is a dynamic parameter, it will come into action within 60 seconds
Once performance monitor is turned on, it starts populating the }Stats control cubes and it updates them every minute.
Well, so far so good...
BUT by default in TM1, ALL cubes in }CubeProperties are set to log ALL transactions. That seems like a sane default, nobody wants to lose track of whom, when and by how much changed a cell in a cube.
So by default, the Performance Monitor will start spamming the transaction log, every minute of your entire server uptime. The problem is most acute with }StatsByCube, it logs one line for every cube, and for every }Element_Attributes_dimension cube.
There is a simple remedy: turn off logging in }CubeProperties for all }Stats cubes (IBM documentation is incomplete)
A quick Turbo Integrator process can do the job too:
CellPutS('NO', '}CubeProperties', '}StatsByClient', 'LOGGING');
CellPutS('NO', '}CubeProperties', '}StatsByCube', 'LOGGING');
CellPutS('NO', '}CubeProperties', '}StatsByCubeByClient', 'LOGGING');
CellPutS('NO', '}CubeProperties', '}StatsByRule', 'LOGGING');
CellPutS('NO', '}CubeProperties', '}StatsByProcess', 'LOGGING');
CellPutS('NO', '}CubeProperties', '}StatsByChore', 'LOGGING');
CellPutS('NO', '}CubeProperties', '}StatsForServer', 'LOGGING');
The size of the spamming may only be a few megabytes per day, although it will have an impact on how long your transaction searches take. Also, the transaction log doesn't rotate for a good reason: you don't want to lose valuable transactions. So it will happily fill up the local drive and after a few months or years the server will finally crash.
If you haven't noticed the issue until now, all is not lost. You don't have to keep all this spam thanks to this bash one-liner that will clean up your 50 gigabyte logs:
for f in tm1s20*log; do awk -F, '$8 != "\"}StatsByCube\""' "$f" > "$f".tmp && mv "$f".tmp "$f"; done # one line to rule them all
You will notice it is removing only "}StatsByCube". I could have added the other }StatsBy cubes, but these are literally 2 orders of magnitude less spammy than }StatsByCube on its own.
Challenge for you: try to achieve the same as the bash one-liner above in any language in less than the 79 characters above. I made it easy, I left a lot of superfluous characters. Constructive comments and answers are welcome.
Documenting TM1
Documenting TM1section dedicated to documenting TM1 with different techniques and tools.
A closer look at chores
A closer look at choresif you ever loaded a .cho file in an editor this is what you would expect:
534,8 530,yyyymmddhhmmss ------ date/time of the first run 531,dddhhmmss ------ frequency 532,p ------ number p of processes to run 13,16 6,"process name" 560,0 13,16 533,x ------ x=1 active/ x=0 inactive
In the 9.1 series it is possible to see from the Server Explorer which chores are active from the chores menu.
However this is not the case in the 9.0 series, also it is not possible to see when and how often the chores are running unless you deactivate them first and edit them. Not quite convenient to say the least.
From the specs above, it is easy to set rules for a parser and deliver all that information in a simple report.
So the perl script attached below is doing just that: listing all chores on your server, their date/time of execution, frequency and activity status.
Procedure to follow:
- Install perl
- Save chores.pl in a folder
- Doubleclick on chores.pl
- A window opens, enter the path to your TM1 server data folder there
- Open resulting file chores.txt created in the same folder as chores.pl
Result:
ACT / date-time / frequency / chore name
X 2005/08/15 04:55:00 007d 00h 00m 00s currentweek
X 2007/04/28 05:00:00 001d 00h 00m 00s DailyS
X 2007/05/30 05:50:00 001d 00h 00m 00s DAILY_UPDATE
X 2007/05/30 05:40:00 001d 00h 00m 00s DAILY_S_UPDATE
X 2005/08/13 20:00:05 007d 00h 00m 00s eweek
X 2006/04/06 07:30:00 001d 00h 00m 00s a_Daily
X 2007/05/30 06:05:00 001d 00h 00m 00s SaveDataAll
X 2007/05/28 05:20:00 007d 00h 00m 00s WEEKLY BUILD
X 2005/05/15 21:00:00 007d 00h 00m 00s weeklystock
2007/05/28 05:30:00 007d 00h 00m 00s WEEKLY_LOAD
A closer look at subsets
A closer look at subsetsif you ever loaded a .sub file (subset) in an editor this is the format you would expect:
283,2 start
11,yyyymmddhhmmss creation date
274,"string" name of the alias to display
18,0 ?
275,d d = number of characters of the MDX expression stored on the next line
278,0 ?
281,b b = 0 or 1 "expand above" trigger
270,d d = number of elements in the subset followed by the list of these elements, this also represents the set of elements of {TM1SubsetBasis()} if you have an MDX expression attached
These .sub files are stored in cube}subs folders for public subsets or user/cube}subs for private subsets.
Often a source of discrepancy in views and reports is the use of static subsets. For example a view was created a while ago, displaying a bunch of customers, but since then new customers got added in the system and they will not appear in that view unless they are manually added to the static subset.
Based on the details above, one could search for all non-MDX/static subsets (wingrep regexp search 275,$ in all .sub files) and identify which might actually need to be made dynamic in order to keep up with slowly changing dimensions.
Beam me up Scotty: 3D Animated TM1 Data Flow
Beam me up Scotty: 3D Animated TM1 Data FlowExplore the structure of your TM1 system through the Skyrails 3D interface:
If you do not have flash, you can have a look at some screenshots
/!\ WARNING: your eyeballs may pop out!
This is basically the same as the previous work with graphviz, except this time it is pushed to 3D, animated and interactive.
So the visualisation engine Skyrails is developed by Ph.D. student Yose Widjaja.
I only wrote the TM1 parser and associated Skyrails script to port a high level view of the TM1 Data flow into the Skyrails realm.
How to proceed:
- Download and unzip skyrails beta 2nd build
- Download and unzip TM1skyrails.zip (attachment below) in the skyraildist2 folder
- In the skyraildist2 folder, doubleclick TM1skyrails.pl (you will need perl installed unless someone wants to provide a compiled .exe of the script with the PAR module)
- Enter the path to (a copy of) your TM1 Data folder
- Skyrails window opens, click on the "folder" icon and click TM1
- If you don't want to install perl, you can still enjoy a preview of the Planning Sample that comes out of the box. Just double-click on raex.exe.
w,s,a,d keys to move the camera
Quick legend:
orange -- cube
blue -- process
light cyan -- file
red -- ODBC source
green sphere -- probably reference to an object that does not exists (anymore)
green edge: intercube rule flow
red edge: process (CellGet/CellPut) floww
Changelog and Downloads:
1.0
1.1 a few mouse gestures added (right click on a node then follow instructions) to get planar (like graphviz) and spherical representations.
1.2 - edges color coded, see legend above
- animated arrows
- gestures to display different flows (no flow/rules only/processes only/all flow)
Dimensions updates mapping
Dimensions updates mappingWhen faced with a large "undocumented" TM1 server, it might become hard to see how dimensions are being updated.
The following perl/graphviz script creates a graph to display which processes are updating dimensions.
The script dimflow.pl is looking for functions updating dimensions (DimensionElementInsert, DimensionCreate...) in .pro files in the TM1 datafolder and maps it all together.
Unfortunately it does not take into account manual editing of dimensions.
This is the result:
Legend:
processes = red rectangles
dimensions = blue bubbles
The above screenshot is probably a good example of why such map can be useful: you can see immediately that several processes are updating the same dimensions.
It might be necessary to have several processes feeding a dimension, though it will be good to review these processes to make sure they are not redundant or conflicting.
Procedure to follow:
- Install perl and graphviz
- Download the script below and rename it to .pl extension
- Doubleclick on it
- Enter the path to your TM1 Data folder (\\servername\datafolder)
- This will create 2 files "dim.dot" and "dim.gif" in the same folder as the perl script
- Open dim.gif with any browser / picture editor
Duplicate Elements in Rollups
Duplicate Elements in RollupsLarge nested rollups can lead to elements being counted twice or more within a rollup.
The following process helps you to find, across all dimensions of your system, all rollups that contain elements consolidated more than once under the rollup.
The code isn't the cleanest and there are probably better methods to achieve the same result so don't hesitate to edit the page or comment.
It proceeds like this:
loop through all dimensions
loop through all rollups of a dimension
if(number of distinct elements in rollup <> number of elements in rollup)
then loop through all alphanumerically sorted elements of the rollup
duplicates are found next to each other
The process takes less than 30 sec to run on a 64bit 9.1.4 system with 212 dimensions, one of the dimensions holds more than a 1000 consolidations and some "decent" nesting (9 levels).
/!\ This process will not work with some TM1 versions because of the MDX function DISTINCT, it has been successfully tested on v. 9.1.4.
DISTINCT does not work properly when applied to expanded rollups on v. 9.0.3
You can just copy/paste the following code in the Prolog window of a process.
Just edit the first line to dump the results where you would like to see them.
/!\ The weight of the duplicated elements is also shown, just in case identical elements cancel each other out with opposite weights.
report = 'D:\duplicate.elements.csv';
#config the line above.
#caveat: empty or consolidations-only dimensions will make this process fail, because empty subsets cannot be created
allrollups = '}All rollups';
subset = '}compare';
maxDim = DimSiz('}Dimensions');
i = 1;
#for each dimension
while (i <= maxDim);
vDim = DIMNM('}Dimensions',i);
#test if there are any rollups
#asciioutput(report, vDim);
SubsetDestroy(vDim, allrollups);
SubsetCreatebyMDX(allrollups,'{TM1FILTERBYLEVEL( {TM1SUBSETALL([' | vDim | '])},0)}');
If(SubsetGetSize(vDim,allrollups) <> DimSiz(vDim));
#get a list of all rollups SubsetDestroy(vDim, allrollups);
SubsetCreatebyMDX(allrollups,'{EXCEPT(TM1SUBSETALL([' | vDim | ']), TM1FILTERBYLEVEL( {TM1SUBSETALL([' | vDim | '])},0))}');
maxRolls = SubsetGetSize(vDim,allrollups);
rollup = 1;
#for each rollup in that dimension while (rollup <= maxRolls);
Consolidation = SubsetGetElementName(vDim, allrollups, rollup);
If(SubsetExists(vDim, subset) = 1);
SubsetDestroy(vDim, subset);
Endif;
SubsetCreatebyMDX(subset, '{DISTINCT(TM1DRILLDOWNMEMBER( {[' | vDim | '].[' | Consolidation | ']}, ALL, RECURSIVE))}' );
Distinct = SubsetGetSize(vDim, subset);
SubsetDestroy(vDim, subset);
SubsetCreatebyMDX(subset, '{TM1DRILLDOWNMEMBER( {[' | vDim | '].[' | Consolidation | ']}, ALL, RECURSIVE)}' );
All = SubsetGetSize(vDim, subset);
if(All <> Distinct);
SubsetDestroy(vDim, subset);
#alphasort consolidation elements so duplicates are next to eachother and a 1-pass is enough to find them all
SubsetCreatebyMDX(subset, '{TM1SORT( {TM1DRILLDOWNMEMBER( {[' | vDim | '].[' | Consolidation | ']}, ALL, RECURSIVE)},ASC) }' );
maxElem = SubsetGetSize(vDim, subset);
prevE = '';
nelem = 1;
while(nelem <= maxElem);
element = SubsetGetElementName(vDim, subset, nelem);
#if 2+ identical elements next to each other then these are the duplicates If(prevE @= element); AsciiOutput(report,'',vDim,Consolidation,element,NumberToString(ELWEIGHT(vDim,Consolidation,element)));
Endif;
prevE = element;
nelem = nelem + 1;
end;
Endif;
rollup = rollup + 1;
end;
SubsetDestroy(vDim, allrollups);
If(SubsetExists(vDim, subset) = 1);
SubsetDestroy(vDim, subset);
Endif;
Endif;
i = i + 1;
end;
Graphing TM1 Data Flow
Graphing TM1 Data FlowThis is the new version of genflow.pl a little parser written in perl that will create a input file for graphviz from your TM1 .pro and .rux files then generate a graph of the data flow in your TM1 server...
(the image has been cropped and scaled down for display, the original image is actually readable)
Legend
ellipses = cubes, rectangles = processes
red = cellget, blue = cellput, green = inter-cube rule
Procedure to follow:
- Install perl and graphviz
- Put the genflow perl script in any folder, make sure it has the .pl extension (not txt)
- Doubleclick on it
- Enter the path to your TM1 Data folder such as: \\servername\datafolder where \\servername\datafolder is the full file path to your TM1 data folder
- Hit return and wait until the window disappears
- This creates 2 files: "flow.dot" and "flow.gif" in the same folder as the perl script
- Open "flow.gif" in any browser or picture editor
Changelog
1.4:
.display import view names along the edges
.display zeroout views
.sources differentiated by shape
1.3:
.CellPut parsing fix
.cubes/processes names displayed 'as is'
This is still quite experimental but this could be useful to view at a glance high-level interactions between your inputs, processes, cubes and rules.
Indexing subsets
Indexing subsetsMaintaining subsets on your server might be problematic. For example you wanted to delete an old subset that you found out to be incorrect and your server replied this:
This is not quite helpful, as it does not say which views are affected and need to be corrected.
Worse is that, as Admin, you can delete any public subset as long as it is not being used in a public view. If it is used in a user's private view, it will be deleted anyway and that private view might become invalid or just won't load.
In order to remediate to these issues, I wrote this perl script indexsubset.pl that will:
- Index all your subsets, including users' subsets.
- Display all unused subsets (i.e. not attached to any existing views)
From the index, you can find out right away in which views a given subset is used.
I suppose the same could be achieved through the TM1 API though you would have to log as every user in turn in order to get a full index of all subsets.
Run from a DOS shell: perl indexsubset.pl \\path\to\TM1\server > mysubsets.txt
Processes running history
Processes running historyOn a large undocumented and mature TM1 server you might find yourself with a lot of processes and you wonder how many of them are still in use or the last time they got run.
The loganalysis.pl script answers these questions for you.
One could take a look at the creation/modification time of the processes in the TM1 Data folder however you would have to sit through pages of the tms1msg.log to get the history of a given process which is what the script below does.
Procedure to follow for TM1 9.0 or 8.x
- Install perl
- Save loganalysis.pl in a folder
- Stop your TM1 service (necessary to beat the windows lock on tm1smsg.log)
- Copy the tm1smsg.log into the same folder where loganalysis.pl is
- Start your TM1 service
- Double click loganalysis.pl
Procedure to follow for TM1 9.1 and above
- Install perl
- Save loganalysis.pl in a folder
- Copy the tm1server.log into the same folder where loganalysis.pl is
- Double click loganalysis.pl
That should display the newly created processes.txt in notepad and that should look like the following:
First, all processes sorted by name and the last run time, user and how many times it ran.
processes by name: 2005load run 2006/02/09 15:02:33 user Admin [x2] ADMIN - Unused Dimensions run 2006/04/26 14:02:58 user Admin [x1] Branch Rates Update run 2006/10/19 15:23:29 user Admin [x1] BrandAnalysisUpdate run 2005/04/11 08:09:13 user Admin [x33] ....
Second, all processes sorted by last run time, user and how many times it ran.
processes by last run: 2005/04/11 08:09:13 user Admin ran BrandAnalysisUpdate [x33] 2005/04/11 10:26:29 user Admin ran LoadDelivery [x1] 2005/04/19 08:44:22 user Admin ran UpdateAntStockage [x19] 2005/04/26 14:18:17 user Admin ran weeklyodbc [x1] 2005/05/12 08:34:16 user Admin ran stock [x1] 2005/05/12 08:37:59 user Admin ran receipts [x1] ....
The case against single children
The case against single childrenI came across hierarchies holding a single child.
While creating a consolidation over only 1 element might make sense in some hierarchies, some people just use consolidations as an alternative to aliases.
Either they just don't know they exist or they come from an age when TM1 did not have aliases yet.
The following process will help you identify all the "single child" elements in your system.
This effectively loops through all elements of all dimensions of your system, so this could be reused to carry out other checks.
#where to report the results
Report = '\\tm1server\reports\single_children.csv';
#get number of dimensions on that system
TotalDim = Dimsiz('}Dimensions');
#loop through all dimensions
i = 1;
While (i <= TotalDim);
ThisDim = DIMNM('}Dimensions',i);
#foreach dimension
#loop through all their elements
j = 1;
While (j <= Dimsiz(ThisDim));
Element = DIMNM(ThisDim,j);
#report the parent if it has only 1 child
If( ELCOMPN(ThisDim, Element) = 1 );
AsciiOutput(Report,ThisDim,Element,ELCOMP(ThisDim,Element,1));
Endif;
#report if consolidation has no child!!!
If( ELCOMPN(ThisDim, Element) = 0 & ELLEV(Thisdim, Element) > 0 );
single = single + 1;
AsciiOutput(Report,ThisDim,DIMNM(ThisDim,j),'NO CHILD!!');
Endif;
j = j + 1;
End;
i = i + 1;
End;
Dynamic tm1p.ini and homepages in Excel
Dynamic tm1p.ini and homepages in ExcelPointing all your users to a single TM1 Admin host is convenient but not flexible if you manage several TM1 services.
Each TM1 service might need different settings and you do not necessarily want users to be able to see the development or test services for example.
mytm1.xla is an Excel addin that logs the users on a predefined server and settings as shown on that graph:
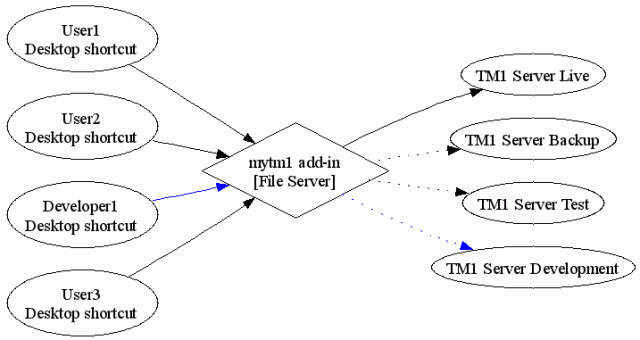
With such a setup, you can switch your users from one server to the other without having to tinker the tm1p.ini files on every single desktop.
This solution probably offers the most flexibility and maintainability as you could add conditional statements to point different groups of users to different servers/settings and even manage and retrieve these settings from a cube through the API.
This addin also includes:
- previous code like the "TM1 freeze" button
- it loads automatically an excel spreadsheet named after the user so each user can customise it with their reports/links for a faster access to their data.
The TM1 macro OPTSET, used in the .xla below, can preconfigure the tm1p.ini with a lot more values.
The official TM1 Help does not reference all the available values though.
Here is a more complete list, you can actually change all the parameters displayed in the Server Explorer File->Options with OPTSET:
AdminHost
DataBaseDirectory
IntegratedLogin
ConnectLocalAtStartup
InProcessLocalServer
TM1PostScriptPrinter
HttpProxyServerHost
HttpProxyServerPort
UseHttpProxyServer
HttpConnectorUrl
UseHttpConnector
and more:
AnsiFiles
GenDBRW
NoChangeMessage
DimensionDownloadMaxSize
this also applies to OPTGET
WARNING:
Make sure that all hosts in the AdminHost line are up and working otherwise Architect/Perspectives will hang for a couple of seconds while trying to connect to these hosts.
Locking and updating locked cubes
Locking and updating locked cubesLocking cubes is a good way to insure your (meta)data is not tampered with.
Right click on the cube you wish to lock, then select Security->Lock.
This now protects the cube contents from TI process and (un)intentional admins' changes.
However, this makes updating your (meta)data more time consuming, as you need to remove the lock prior to updating the cube.
Hopefully, the function CubeLockOverride allows you to automate that step. The following TI code demonstrates this,
.lock a cube
.copy/paste the code in a TI Prolog tab
.change the parameters to fit your system
.execute:
# uncomment / comment the next line to see the process win / fail
CubeLockOverride(1);
Dim = 'Day';
Element = 'Day 01';
Attribute = 'Dates 2010';
NewValue = 'Saint Glinglin';
if( CellIsUpdateable('}ElementAttributes_' | Dim, Element, Attribute) = 1);
AttrPutS(NewValue, Dim, Element, Attribute);
else;
ItemReject('could not unlock element ' | Element | ' in ' | Dim);
endif;
Note: CubeLockOverride is in the reserved words listed in the TM1 manual but its function seems to be only documented in the 8.4.5 releases notes.
This works from 8.4.5 to the more recent 9.x series
Managing the licenses limit
Managing the licenses limitOne day you might face or already faced the problem of too many licences being in use and as a result additional users cannot log in.
Also on a default setup, nothing stops users from opening several tm1web/perspectives sessions and reach the limit of licenses.
So in order to prevent that:
.open the cube }ClientProperties, change all users' MaximumPorts to 1
.in your tm1s.cfg add that line, it will timeout all idle connections after 1 hour:
IdleConnectionTimeOutSeconds = 3600
To see who's logged on:
.use tm1top
or
.open the cube }ClientProperties
all logged users have the STATUS measure set to "ACTIVE"
or
.in server manager (rightclick server icon), click "Select clients..." to get the list
To kick some users without taking the server down:
in server explorer right click on your server icon -> Server Manager
select disconnect clients and "Select clients..."
then OK and they are gone.
Unfortunately there is still no workaround for the admin to log in when users take all the slots allowed.
Monitor rules and processes
Monitor rules and processesChanging a rule or process in TM1 does not show up in the logs.
That is fine as long as you are the only Power User able to tinker with these objects.
Unfortunately, it can get out of hand pretty quickly as more power users join the party and make changes that might impact other departments data.
So here goes a simple way to report changes.
The idea is to compare the current files on the production server with a backup from the previous day.
You will need:
- Access to the live TM1 Data Folder
- Access to the last daily backup
- A VB script to email results you can find one there
- diff, egrep and unix2dos
Save these files in D:\TM1DATA\BIN for example, or some path accessible to the TM1 server.
In the same folder create a diff.bat file, replace all the TM1DATA paths to your configuration:
@echo off cd D:\TM1DATA\BIN del %~1 rem windows file compare fc is just crap, must fallback to the mighty GNU binutils diff -q "\\liveserver\TM1DATA" "\\backupserver\TM1DATA" | egrep "\.(pro|RUX|xdi|xru|cho)" > %~1 rem make it notepad friendly, i.e. add these horrible useless CR chars at EOL, it's 2oo8 but native windows apps are just as deficient as ever unix2dos %~1 rem if diff is not empty then email results if %~z1 GTR 1 sendattach.vbs mailserver 25 from.email to.email "[TM1] daily changes log" " " "D:\TM1DATA\BIN\%~1"
Now you can set a TM1 process with the following line to run diff.bat and schedule it from a chore.
ExecuteCommand('cmd /c D:\TM1DATA\BIN\diff.bat diff.txt',0);
Best is to run the process at close of business, just before creating the backup of the day.
And you should start receiving emails like these:
Files \\liveserver\TM1DATA\Check Dimension CollectionCat.pro and \\backupserver\TM1DATA\Check Dimension CollectionCat.pro differ Files \\liveserver\TM1DATA\Productivity.RUX and \\backupserver\TM1DATA\Productivity.RUX differ Only in \\liveserver\TM1DATA: Update Cube Branch Rates.pro
In this case we can see that the rules from the Productivity cube have changed today.
Monitoring chores by email
Monitoring chores by emailUsing the script in the Send Email Attachments article, it is possible to set it up to automatically email the Admin when a process in a chore fails.
Here is how to proceed:
1. Setup admin email process
First we create a process to add an email field to the ClientProperties cube and add an email to forward to the Admin.
1.1 create a new process
---- Advanced/Parameters Tab, insert this parameter:
AdminEmail / String / / "Admin Email?"
--- Advanced/Prolog tab
if(DIMIX('}ClientProperties','Email') = 0);
DimensionElementInsert('}ClientProperties','','Email','S');
Endif;
--- Advanced/Epilog tab
CellPutS(AdminEmail,'}ClientProperties','Admin','Email');
1.2 Save and Run
2. Create monitor process
---- Advanced/Prolog tab
MailServer = 'smtp.mycompany.com';
LogDir = '\\tm1server\e$\TM1Data\Log';
ScriptDir = 'E:\TM1Data\';
NumericGlobalVariable( 'ProcessReturnCode');
If(ProcessReturnCode <> ProcessExitNormal());
If(ProcessReturnCode = ProcessExitByChoreQuit());
Status = 'Exit by ChoreQuit';
Endif;
If(ProcessReturnCode = ProcessExitMinorError());
Status = 'Exit with Minor Error';
Endif;
If(ProcessReturnCode = ProcessExitByQuit());
Status = 'Exit by Quit';
Endif;
If(ProcessReturnCode = ProcessExitWithMessage());
Status = 'Exit with Message';
Endif;
If(ProcessReturnCode = ProcessExitSeriousError());
Status = 'Exit with Serious Error';
Endif;
If(ProcessReturnCode = ProcessExitOnInit());
Status = 'Exit on Init';
Endif;
If(ProcessReturnCode = ProcessExitByBreak());
Status = 'Exit by Break';
Endif;
vbody= 'Process failed: '|Status| '. Check '|LogDir;
Email = CellGetS('}ClientProperties','Admin','Email');
If(Email @<> '');
S_Run='cmd /c '|ScriptDir|'\SendMail.vbs '| MailServer |' 25 '|Email|' '|Email|' "TM1 chore alert" "'|vBody|'"';
ExecuteCommand(S_Run,0);
Endif;
Endif;
2.1. adjust the LogDir, MailServer and ScriptDir values to your local settings
3. insert this monitor process in chore
This monitor process needs to be placed after every process that you would like to monitor.
How does it work?
Every process, after execution, returns a global variable "ProcessReturnCode", and that variable can be read by a process running right after in a chore.
The above process checks for that return code and pipes it to the mail script if it happens to be different from the normal exit code.
If you have a lot of processes in your chore, you will probably prefer to use the ExecuteProcess command and the check return code over a loop. That method is explained here.
Monitoring chores by email part 2
Monitoring chores by email part 2Following up on monitoring chores by email, we will take a slightly different approach this time.
We use a "metaprocess" to execute all the processes listed in the original chore, check their return status and eventually act on it.
This allows for maximum flexibility as you can get that controlling process to react differently to any exit status of any process.
1. Create process ProcessCheck
--- Data Source tab
choose ASCII, Data Source Name points to an already existing chore file, for example called Daily Update.cho
--- Variables tab
Variables tab has to be that way:
--- Advanced/Data tab
#mind that future TM1 versions might use a different format for .cho files and that might break this script
If(Tag @= '6');
MailServer = 'mail.myserver.com';
LogDir = '\\server\f$\TM1Data\myTM1\Log';
#get the process names from the deactivated chore
Process=Measure;
NumericGlobalVariable( 'ProcessReturnCode');
StringGlobalVariable('Status');
ErrorCode = ExecuteProcess(Process);
If(ErrorCode <> ProcessExitNormal());
If(ProcessReturnCode = ProcessExitByChoreQuit());
Status = 'Exit by ChoreQuit';
#Honour the chore flow so stop here and quit too
ChoreQuit;
Endif;
If(ProcessReturnCode = ProcessExitMinorError());
Status = 'Exit with Minor Error';
Endif;
If(ProcessReturnCode = ProcessExitByQuit());
Status = 'Exit by Quit';
Endif;
If(ProcessReturnCode = ProcessExitWithMessage());
Status = 'Exit with Message';
Endif;
If(ProcessReturnCode = ProcessExitSeriousError());
Status = 'Exit with Serious Error';
Endif;
If(ProcessReturnCode = ProcessExitOnInit());
Status = 'Exit on Init';
Endif;
If(ProcessReturnCode = ProcessExitByBreak());
Status = 'Exit by Break';
Endif;
vbody=Process|' failed: '|Status|'. Check details in '|LogDir;
Email = CellGetS('}ClientProperties','Admin','Email');
If(Email @<> '');
S_Run='cmd /c F:\TM1Data\CDOMail.vbs '| MailServer |' 25 '|Email|' '|Email|' "TM1 chore alert" "'|vBody|'"';
ExecuteCommand(S_Run,0);
Endif;
Endif;
Endif;
The code only differs from the first method when the process returns a ChoreQuit exit. Because we will be running the chore Daily Update from another chore, the ChoreQuit will not apply to the later, so we need to specify it explicitly to respect the flow and stop at the same point.
2. Create chore ProcessCheck
just add the process above and set it to the same frequency and time as the Daily Update chore that you want to monitor
3. Deactivate Daily Update
since the ProcessCheck chore will run the Daily Update chore there is no need to execute Daily Update another time
Monitoring users logins
Monitoring users loginsA quick way to monitor users login/logout on your system is to log the STATUS value (i.e. ACTIVE or blank) from the }ClientProperties cube.
View->Display Control Objects
Cubes -rightclick- Security Assignments
browse down to the }ClientProperties cube and make sure the Logging box is checked
tm1server -rightclick- View Transaction Log
Select Cubes: }ClientProperties
All the transactions are stored in the tm1s.log file, however if you are on a TM1 version prior to version 9.1 and hosted on a Windows server, the file will be locked.
A "Save Data" will close the log file and add a timestamp to its name, so you can start playing with it.
/!\ This trick does not work in TM1 9.1SP3 as it does not update the STATUS value.
Pushing data from an iSeries to TM1
Pushing data from an iSeries to TM1TM1 chore scheduling is frequency based, i.e. it will run and try to pull data after a predefined period of time regardless of the availability of the data at the source. Unfortunately it can be a hit or miss and it can even become a maintenance issue when Daylight Saving Time come into play.
Ideally you would need to import or get the data pushed to TM1 as soon as it is available. The following article shows one way of achieving that goal with an iSeries as the source...
prerequesites on the TM1 server:
- Mike Cowie's TIExecute
- iSeries Client Access components (iSeries Access for Windows Remote Command service)
Procedure to follow
- Drop TM1ChoreExecute, TM1ProcessExecute, associated files and the 32bit TM1 API dlls in a folder on the TM1 server (see readme in the zip for details)
- Start iSeries Access for Windows Remote Command on the TM1 server, set as automatic and select a user that can execute the TM1ChoreExecute
- In client access setup: set remote incoming command "run as system" + "generic security"
- On your iSeries, add the following command after all your queries/extracts:
RUNRMTCMD CMD('start D:\path\to\TM1ChoreExecute AdminServer TM1Server UserID Password ChoreName') RMTLOCNAME('10.xx.x.xx' *IP) WAITTIME(10)
10.xx.x.xx IP of your TM1 server
D:\path\to path where the TM1ChoreExecute is stored
AdminServer name of machine running the Admin Server service on your network.
TM1Server visible name of your TM1 Server (not the machine name of the machine running TM1.
UserID TM1 user ID with credentials to execute the chore.
Password TM1 user ID's password to the TM1 Server.
ChoreName name of requested chore to be run to load data from the iSeries.
You should consider setting a user/pass to restrict access to the iSeries remote service and avoid abuse.
But ideally an equivalent of TM1ChoreExecute should be compiled and executed directly from the iSeries.
Quick recovery from data loss
Quick recovery from data lossA luser just ran that hazardous process or spreading on the production server and as a result trashed loads of data on your beloved server.
You cannot afford to take the server down to get yesterday's backup and they need the data now...
Fear not, the transaction log is here to save the day.
- In server explorer, right click on server->View Transaction Log
- Narrow the query as much as you can to the time/client/cube/measures that you are after
- /!\ Mind the date is in north-american format mm/dd/yyyy
- Edit->Select All
- Edit->Back Out will rollback the selected entries
Alternatively, you could get the most recent backup of the corresponding .cub of the "damaged" cube:
- In server explorer: right-click->unload cube
- Overwrite the .cub with the backed up .cub
- Reload the cube from server explorer by opening any view from it
Store any type of files in the Applications folder
Store any type of files in the Applications folderThe Applications folder is great but limited to views and xls files, well not anymore.
The following explains how to make available just any file in your Applications folders.
1. create a file called myfile.blob in }Applications\ on your TM1 server
it should contain the following 3 lines:
ENTRYNAME=tutorial.pdf
ENTRYTYPE=blob
ENTRYREFERENCE=TM!:///blob/public/.\}Externals\tutorial.pdf
2. place your file, tutorial.pdf in this case, in }Externals or whatever path you defined in ENTRYREFERENCE
3. restart your TM1 service
ENTRYNAME is the name that will be displayed in Server Explorer.
ENTRYREFERENCE is the path to your actual file. The file does not need to be in the folder }Externals but the server must be able to access it
/!\ avoid large files, there is no sign to tell you to wait while loading, impatient users might click several times on the file and unvoluntarily flood the server or themselves.
/!\ add the extension in ENTRYNAME to avoid confusion, although it is not a .xls file, it will be displayed with an XLS icon.
TM1 Sudoku
TM1 SudokuBeyond the purely ludic and mathematical aspects of sudoku, this code demonstrates how to set up dimensions, cubes, views, cell formating, security at elements and cells levels all through Turbo Integrator in just one process.
Thanks to this application, you can demonstrate your TM1 ROI: none of your company employees will need to shell out £1 ever again for their daily sudoku from the Times.
Alternatively, you could move your users to a "probation" group before they start their shift. It is only by completing successfully the sudoku that the users will be moved back to their original group.
This way you can insure your company employees are mentally fit to carry out changes to the budget, especially after last evening ethylic abuses down the pub.
Of course it exists many sudoku available for Excel, this is one is to be played primarily from the cube viewer, but you could also slice the view and play it from Excel too.
How to install:
.Save the processes Create Sudoku.pro and Check Sudoku.pro in your TM1 folder and reload your server or copy the code directly to new turbo integrator processes.
.Execute "Create Sudoku". That creates the cube, default view and new puzzle in less than a second.
The user can input numbers in the "input" grid only where there are zeroes. The "solution" grid cannot be read by default.
.Execute "Check Sudoku" to verify your input grid matches the solution.
If you are logged under an admin account, you will not see any cells locked, you need to be under the group defined in the process to see the cells properly locked.
You might want to change the default group allowed to play and the number of initial pairs that are blanked in order to increase difficulty.
The algorithm provided to generate the sudoku could be quickly modified to solve by brute force any sudoku. Provided the sudoku grid is valid, it will find the solution, however some sudokus with too many empty cells will have more than one solution.
TM1 services on the command line
TM1 services on the command lineremoving a TM1 service
in a DOS shell:
go to the \bin folder where TM1 is installed then:
tm1sd -remove -n "TM1 Service"
where "TM1 Service is the name of an existing TM1 service
or: sc delete "TM1 Service"
removing the TM1 Admin services
sc delete tm1admsdx64
sc delete TM1ExcelService
installing a TM1 service
in a DOS shell:
go to the \bin folder where TM1 is installed then:
tm1sd -install -n "TM1 Service" -z DIRCONFIG
where DIRCONFIG is the absolute path where the tm1s.cfg of your TM1 Service is stored
manually starting a TM1 service
from a DOS shell in the \bin folder of the TM1 installation:
tm1s -z DIRCONFIG
remotely start a TM1 service
sc \\TM1server start "TM1 service"
remotely stop a TM1 service
sc \\TM1server stop "TM1 service"
TM1Top
TM1TopTM1Top provides realtime monitoring of your TM1 server, pretty much like the GNU top command.
It is bundled with TM1 only from version 9.1. You might have to ask your support contact to get it or get Ben Hill's TM1Top below.
. Dump the files in a folder
. Edit tm1top.ini, replace myserver and myadminhost with your setup
servername=myserver adminhost=myadminhost refresh=5 logfile=C:\tm1top.log logperiod=0 logappend=T
. Run the tm1top.exe
Commands:
X exit
W write display to a file
H help
V verify/login to allow cancelling jobs
C cancel threads, you must first login to use that command
Keep in mind all it does is to insert a "ProcessQuit" command in the chosen thread.
Hence it will not work if the user is calculating a large view or a TI is stuck in a loop where it never reads the next data record, as the quit command is entered for the next data line rather than the next line of code. Then your only option becomes to terminate the user's connection with the server manager or API. (thanks Steve Vincent).
Ben "Kyro" Hill did a great job developing a very convenient GUI TM1Top.
WebSphere Liberty Profile SSL configuration for TM1Web
WebSphere Liberty Profile SSL configuration for TM1WebTL;DR Skip directly to the bottom of the article to find out the fastest and most secure SSL configuration for WLP/TM1Web. Otherwise, read on to understand the how and the why.
TM1Web also known as "Planning Analytics Spreadsheet Services" is a web app serving websheets through the IBM WebSphere Liberty Profile webserver currently operating under Java Running Environment 1.8.0.
The encryption to communicate with that WLP server is handled by a choice of ciphersuites to be configured in <TM1Web_install>\wlp\usr\webserver\server.xml
One line of particular interest regarding security and compliance is the following setting the enabled ciphers:
<ssl id="CAM" keyStoreRef="CAMEncKeyStore" serverkeyAlias="encryption" enabledciphers="SSL_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 SSL_ECDHE_ECDSA_WITH_AES_256 GCM_SHA384" sslProtocol="TLSv1.2"/>However, the IBM documentation fails to provide the list of available ciphersuites. If you are familiar with ciphersuites, it should be an easy guess after a few online searches. But you can also unveil the exact list of cipher suites by compiling and running the linked Ciphers.java code.
javac Ciphers.java
java CiphersI will spare you all the work of finding, downloading, installing the correct java compiler, compiling the code and finally executing it. So, here is the list of all the ciphersuites available for TM1Web. The recommended ciphersuites are set in bold.
TLS v1.2
- SSL_DHE_DSS_WITH_AES_128_CBC_SHA
- SSL_DHE_DSS_WITH_AES_128_CBC_SHA256
- SSL_DHE_DSS_WITH_AES_128_GCM_SHA256
- SSL_DHE_DSS_WITH_AES_256_CBC_SHA
- SSL_DHE_DSS_WITH_AES_256_CBC_SHA256
- SSL_DHE_DSS_WITH_AES_256_GCM_SHA384
- SSL_DHE_RSA_WITH_AES_128_CBC_SHA
- SSL_DHE_RSA_WITH_AES_128_CBC_SHA256
- SSL_DHE_RSA_WITH_AES_128_GCM_SHA256
- SSL_DHE_RSA_WITH_AES_256_CBC_SHA
- SSL_DHE_RSA_WITH_AES_256_CBC_SHA256
- SSL_DHE_RSA_WITH_AES_256_GCM_SHA384
- SSL_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
- SSL_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
- SSL_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
- SSL_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
- SSL_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384
- SSL_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
- SSL_ECDHE_RSA_WITH_AES_128_CBC_SHA
- SSL_ECDHE_RSA_WITH_AES_128_CBC_SHA256
- SSL_ECDHE_RSA_WITH_AES_128_GCM_SHA256
- SSL_ECDHE_RSA_WITH_AES_256_CBC_SHA
- SSL_ECDHE_RSA_WITH_AES_256_CBC_SHA384
- SSL_ECDHE_RSA_WITH_AES_256_GCM_SHA384
- SSL_ECDH_ECDSA_WITH_AES_128_CBC_SHA
- SSL_ECDH_ECDSA_WITH_AES_128_CBC_SHA256
- SSL_ECDH_ECDSA_WITH_AES_128_GCM_SHA256
- SSL_ECDH_ECDSA_WITH_AES_256_CBC_SHA
- SSL_ECDH_ECDSA_WITH_AES_256_CBC_SHA384
- SSL_ECDH_ECDSA_WITH_AES_256_GCM_SHA384
- SSL_ECDH_RSA_WITH_AES_128_CBC_SHA
- SSL_ECDH_RSA_WITH_AES_128_CBC_SHA256
- SSL_ECDH_RSA_WITH_AES_128_GCM_SHA256
- SSL_ECDH_RSA_WITH_AES_256_CBC_SHA
- SSL_ECDH_RSA_WITH_AES_256_CBC_SHA384
- SSL_ECDH_RSA_WITH_AES_256_GCM_SHA384
- SSL_RSA_WITH_AES_128_CBC_SHA
- SSL_RSA_WITH_AES_128_CBC_SHA256
- SSL_RSA_WITH_AES_128_GCM_SHA256
- SSL_RSA_WITH_AES_256_CBC_SHA
- SSL_RSA_WITH_AES_256_CBC_SHA256
- SSL_RSA_WITH_AES_256_GCM_SHA384
TLS v1.3
- TLS_AES_128_GCM_SHA256
- TLS_AES_256_GCM_SHA384
- TLS_CHACHA20_POLY1305_SHA256
- TLS_DHE_RSA_WITH_CHACHA20_POLY1305_SHA256
- TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
- TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
- TLS_EMPTY_RENEGOTIATION_INFO_SCSV
So what does this all mean? A ciphersuite is a combination of algorithms used in the SSL/TLS protocol for secure communication. Each ciphersuite name is structured to describe the algorithmic contents of it.
For example, the ciphersuite `SSL_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384` is built with the following components:
- SSL: This indicates the protocol version. In this case, it's TLS v1.2 (Transport Layer Security).
- ECDHE: This stands for Elliptic Curve Diffie-Hellman Ephemeral. It's the key exchange method used in this ciphersuite. Diffie-Hellman key exchanges which use ephemeral (generated per session) keys provide forward secrecy, meaning that the session cannot be decrypted after the fact, even if the server's private key is known. Elliptic curve cryptography provides equivalent strength to traditional public-key cryptography while requiring smaller key sizes, which can improve performance.
- ECDSA: This stands for Elliptic Curve Digital Signature Algorithm. It's the algorithm used for server authentication. The server's certificate must contain an ECDSA-capable public key.
- AES_256: This indicates the symmetric encryption cipher used. In this case, it's AES (Advanced Encryption Standard) with 256-bit keys. This is reasonably fast and not broken.
- GCM: This stands for Galois/Counter Mode. It's a mode of operation for symmetric key cryptographic block ciphers. It's used here for the symmetric encryption cipher.
- SHA384: This is the hash function used. It's used for the Message Authentication Code (MAC) feature of the TLS ciphersuite. This is what guarantees that each message has not been tampered with in transit. SHA384 is a great choice.
Some ciphersuites in the list above are not recommended because of the following obsolete algorithms:
- DHE_DSS: This is an old key exchange algorithm that uses the Diffie-Hellman key exchange and the DSS (Digital Signature Standard) algorithm for digital signatures. It's not recommended for use because DSS is considered less secure than ECDSA (Elliptic Curve Digital Signature Algorithm), and Diffie-Hellman is not as efficient as Elliptic Curve Diffie-Hellman.
- RSA as server authentication: While RSA is still widely used, it's not recommended for use as both the key exchange and authentication algorithm. This is because it does not provide Perfect Forward Secrecy.
- CBC: This is a mode of operation for symmetric key cryptographic block ciphers. It's not recommended for use because it's vulnerable to padding oracle attacks, which allow an attacker to decrypt ciphertext without knowing the encryption key. Instead, it's recommended to use GCM (Galois/Counter Mode) or CCM (Counter with CBC-MAC).
- SHA (also known as SHA1): This is a hash function that is not recommended for use because it's considered to be weak and vulnerable to collision attacks. Instead, it's recommended to use SHA-256 or SHA-384.
faster and more secure TM1Web with TLS v1.3
TLS 1.3 offers several performance improvements over TLS 1.2. One of the key differences is the faster TLS handshake. Under TLS 1.2, the initial handshake was carried out in clear text, requiring encryption and decryption, which added considerable overhead to the connection. TLS 1.3, on the other hand, adopted server certificate encryption by default, which reduced this overhead and allowed for faster, more responsive connections.
Another performance improvement in TLS 1.3 is the Zero Round-Trip Time (0-RTT) feature. This feature eliminates an entire round-trip on the handshake, saving time and improving overall site performance. When accessing a site that has been visited previously, a client can send data on the first message to the server by leveraging pre-shared keys (PSK) from the prior session.
TLS 1.3 offers more robust security features compared to TLS 1.2. It supports cipher suites that do not include key exchange and signature algorithms, which are used in TLS 1.2. TLS 1.2 used ciphers with cryptographic weaknesses that had security vulnerabilities. TLS 1.3 also eliminates the security risk posed by a static key, which can compromise security if accessed illicitly. Furthermore, TLS 1.3 uses the Diffie-Hellman Ephemeral algorithm for key exchange, which generates a unique session key for every new session. This session key is one-time and is discarded at the end of every session, enhancing forward secrecy.
So, an optimal configuration for WLP server.xml will be:
<ssl id="CAM" keyStoreRef="CAMEncKeyStore" serverkeyAlias="encryption" enabledciphers="TLS_AES_128_GCM_SHA256 TLS_AES_256_GCM_SHA384 TLS_CHACHA20_POLY1305_SHA256 TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256" sslProtocol="TLSv1.3">Unfortunately, I haven't found a way to have both TLSv1.2 and TLSv1.3 protocols available at the same time in that configuration file. If you know how, please leave a comment with the details.
You can easily check the configuration is correct in Chrome, with Developer Tools -> Security -> Security Overview -> Connection: "The connection to this site is encrypted and authenticated using TLS 1.3"
On a side note, the configuration file for TM1Web is located at <TM1Web_install>\webapps\tm1web\WEB-INF\configuration\tm1web_config.xml.
tm1s.cfg parameters cheatsheet
tm1s.cfg parameters cheatsheetThe number of parameters in the tm1s.cfg has been steadily rising as more features have been made available over the years in TM1. So, a cheatsheet summarising all these parameters can help as an overview of the different settings that a TM1 server can be configured with.
This cheatsheet is now available in the following formats:
- csv so you can build your own variations of the cheatsheet
- tm1s.cfg including all parameters, only the required parameters are uncommented, every parameter is set to its known default value (as of 2023-02-14 and according to the IBM online documentation). There should not be a need to explicitly define a parameter when you just want to stick to the default value. However, be cautious that IBM may change default values and that could lead to issues when upgrading versions.
- md markdown to save in your personal knowledge management repository full of markdown files to ripgrep through fzf.vim
- pdf for an allegedly pretty overview (coming soon)
- html below or here on its own that you can "Save as" to use as a local copy.
The cheatsheet is generated with python scripts (coming soon) responsible for the conversion of the csv file to a pandas dataframe and then exported to different formats. The csv file currently holds the following fields:
- parameter: name of the parameter
- optional: indicates if the parameter is either required or optional.
- restart: indicates if the parameter is either dynamic or static 🔄, in the later case, it requires a service restart when its value has been modified
- url: URL address of the official IBM Planning Analytics documentation for that parameter
- default: default value of that parameter when it is not explicitly declared
- type: type of that parameter (bool, int, float, str, time). This will be useful for scripts checking tm1s.cfg validity
- context: arbitrary categorisation for the context of the parameter e.g. it can be Network related, Rules related, etc..
- dependency: that may hold the name of another parameter that the current parameter may rely on to operate
- description: short description about what the parameter does
The categorisation is completely arbitrary, most parameters could fit in several categories, so I just picked one that seemed most appropriate. This is a limitation and probably something to look into for the design of future versions of that csv file.
And finally, the tm1s.cfg parameters cheatsheet in html.
Note that there is a drop down menu at the top of the Context column. This allows you to show only parameters that relate to a specific aspect of your TM1 server. If you are on mobile, you probably need to rotate your screen for a wide display in order to display all 5 columns.
tm1s.cfg parameters cheatsheet
parameters in bold are required.
🔄 = static parameter, the TM1 service must be restarted for the new value of that parameter to take effect.
| parameter | default | restart | context |
description |
|---|---|---|---|---|
| AdminHost | 🔄 | Network | computer name or IP address of the Admin Host on which an Admin Server is running. | |
| AllowReadOnlyChoreReschedule | F | 🔄 | Chores | Provides users with READ access to a chore and the ability to activate deactivate and reschedule chores. |
| AllowSeparateNandCRules | F | 🔄 | Rules | if true then rule expressions for N: and C: levels can be on separate lines using identical AREA definitions. |
| AllRuleCalcStargateOptimization | F | 🔄 | Rules | if true then it can improve performance in calculating views that contain only rule-calculated values. In some unique cases enabling this parameter can result in performance degradation so you should test the effect of the parameter in a development environment before deploying to your production environment. |
| ApplyMaximumViewSizeToEntireTransaction | F | Views | Applies MaximumViewSize to the entire transaction instead of to individual calculations. | |
| AuditLogMaxFileSize | 100 MB | Logs and Messages | maximum file size that an audit log file can grow to before it is closed and a new file is created. | |
| AuditLogMaxQueryMemory | 100 MB | Logs and Messages | maximum amount of memory that TM1 can use when running an audit log query and retrieving the set of results. | |
| AuditLogOn | F | Logs and Messages | if true turns audit logging on. | |
| AuditLogUpdateInterval | 60 | Logs and Messages | maximum amount of minutes that TM1 waits before moving the events from the temporary audit file into the final audit log. | |
| AutomaticallyAddCubeDependencies | T | 🔄 | Rules | Determines if cube dependencies are set automatically or if you must manually identify the cube dependencies for each cube. |
| CacheFriendlyMalloc | F | 🔄 | Cache | Allows for memory alignment that is specific to the IBM Power Platform. |
| CalculationThresholdForStorage | 50 | Rules | minimum number of rule calculations required for a single cell or Stargate view beyond which TM1 stores the calculations for use during the current server session. | |
| CAMPortalVariableFile | 🔄 | Cognos Analytics | The path to the variables_TM1.xml file in your IBM Cognos installation. | |
| CAMUseSSL | F | 🔄 | Cognos Analytics | all communications between TM1 and the Cognos Analytics server must use SSL. |
| CheckCAMClientAlias | T | Cognos Analytics | When audit logging is enabled with the AuditLogOn parameter the CheckCAMClientAlias parameter determines whether user modifications within Cognos Authentication Manager (CAM) groups are written to the audit log. | |
| CheckFeedersMaximumCells | 3000000 | Rules | Limits the number of cells checked by the Check Feeders option in the Cube Viewer. | |
| ClientCAMURI | Cognos Analytics | The URI the Cognos Server Connection uses to authenticate TM1 clients. | ||
| ClientExportSSLSvrCert | F | 🔄 | Authentication and Encryption | TM1 client should retrieve the certificate authority certificate which was originally used to issue TM1 certificate from the MS Windows certificate store. |
| ClientExportSSLSvrKeyID | 🔄 | Authentication and Encryption | identity key used by a TM1 client to export the certificate authority certificate which was originally used to issue TM1 certificate from the MS Windows certificate store. | |
| ClientMessagePortNumber | 🔄 | Network | secondary port used to accept client messages concerning the progress and ultimate cancellation of a lengthy operation without tying up thread reserves. | |
| ClientPingCAMPassport | 900 | Cognos Analytics | interval in seconds that a client should ping the Cognos Authentication Management server to keep their passport alive. | |
| ClientPropertiesSyncInterval | Logs and Messages | frequency (in seconds) at which client properties are updated in the }ClientProperties control cube. Set to 1800 seconds to update cube every 30 minutes. | ||
| ClientVersionMaximum | Network | maximum client version that can connect to TM1. | ||
| ClientVersionMinimum | 8.4.00000 | Network | minimum client version that can connect to TM1. | |
| ClientVersionPrecision | 0 | Network | precisely identify the minimum and maximum versions of clients that can connect to TM1. | |
| CognosMDX.AggregateByAncestorRef | F | 🔄 | Cognos Analytics | When possible replaces aggregation over a member set with a reference to an ancestor if the aggregated member set comprises a complete set of descendants and all members have the weight 1. |
| CognosMDX.CellCacheEnable | T | 🔄 | Cognos Analytics | Allows the IBM Cognos MDX engine to modify TM1 consolidation and calculation cell cache strategies. |
| CognosMDX.PrefilterWithPXJ | F | 🔄 | Cognos Analytics | Expands the data source provider cross join approach to nested filtered sets. |
| CognosMDX.SimpleCellsUseOPTSDK | T | 🔄 | Cognos Analytics | Applies IBM Cognos MDX engine consolidation and calculation cell cache strategies to all cells in query results. |
| CognosMDX.UseProviderCrossJoinThreshold | 0 | 🔄 | Cognos Analytics | Applies the data source provider cross join strategy even if it is not explicitly enabled in Cognos Analytics. |
| CognosTM1InterfacePath | 🔄 | Cognos Analytics | location of the IBM Cognos Analytics server to use when importing data from a Cognos Package to TM1 configuration using the Package Connector. | |
| CreateNewCAMClients | T | Cognos Analytics | The CreateNewCAMClients server configuration parameter determines how TM1 configuration handles an attempt to log on to the server with CAM credentials in the absence of a corresponding TM1 client. | |
| DataBaseDirectory | 🔄 | Files | data directory from which the database loads cubes dimensions and other objects. | |
| DefaultMeasuresDimension | F | 🔄 | Cubes | Identifies if a measures dimension is created. TM1 does not require that a measures dimension be defined for a cube. You can optionally define a measures dimension by modifying the cube properties. |
| DisableMemoryCache | F | 🔄 | Cache | Disables the memory cache used by TM1 memory manager. |
| DisableSandboxing | F | Sandboxes | if false then users have the ability to use sandboxes across the server. | |
| DownTime | Chores | time when the database will come down automatically. | ||
| EnableNewHierarchyCreation | F | 🔄 | Dimensions | multiple hierarchy creation is enabled or disabled. |
| EnableSandboxDimension | F | Sandboxes | virtual sandbox dimension feature is enabled or disabled. | |
| EnableTIDebugging | F | Turbo Integrator | TurboIntegrator debugging capabilities are enabled or disabled. | |
| EventLogging | T | Logs and Messages | event logger is either turned on or off. | |
| EventScanFrequency | 1 | Logs and Messages | period to check the collection of threads where 1 is the minimum number and 0 disables the scan. | |
| EventThreshold.PooledMemoryInMB | 0 | Logs and Messages | threshold for which a message is printed for the event that the database's pooled memory exceeds a certain value. | |
| EventThreshold.ThreadBlockingNumber | 5 | Logs and Messages | warning is printed when a thread blocks at least the specified number of threads. | |
| EventThreshold.ThreadRunningTime | 600 | Logs and Messages | warning is printed when a thread has been running for the specified length of time. | |
| EventThreshold.ThreadWaitingTime | 20 | Logs and Messages | warning is printed when a thread has been blocked by another thread for the specified length of time. | |
| ExcelWebPublishEnabled | F | TM1Web | Enables the publication of MS Excel files to IBM Cognos TM1 Web as well as the export of MS Excel files from TM1 Web when MS Excel is not installed on the web server. Enable the ExcelWebPublishEnabled parameter when you have TM1 10.1 clients that connect to TM1 10.2.2 servers. | |
| FileRetry.Count | 5 | Logs and Messages | number of retry attempts. | |
| FileRetry.Delay | 2000 | Logs and Messages | time delay between retry attempts. | |
| FileRetry.FileSpec | Logs and Messages | |||
| FIPSOperationMode | 2 | 🔄 | Authentication and Encryption | Controls the level of support for Federal Information Processing Standards (FIPS). |
| ForceReevaluationOfFeedersForFedCellsOnDataChange | F | 🔄 | Rules | When this parameter is set a feeder statement is forced to be re-evaluated when data changes. |
| HTTPOriginAllowList | Network | a comma-delimited list of external origins (URLs) that are trusted and can access TM1. | ||
| HTTPPortNumber | 5001 | 🔄 | Network | port number on which TM1 listens for incoming HTTP(S) requests. |
| HTTPRequestEntityMaxSizeInKB | 32 | Network | This TM1 configuration parameter sets the maximum size for an HTTP request entity that can be handled by TM1. | |
| HTTPSessionTimeoutMinutes | 20 | Authentication and Encryption | timeout value for authentication sessions for TM1 REST API. | |
| IdleConnectionTimeOutSeconds | Authentication and Encryption | timeout limit for idle client connections in seconds. | ||
| IndexStoreDirectory | 🔄 | Files | Added in v2.0.5 Designates a folder to store index files including bookmark files. | |
| IntegratedSecurityMode | Authentication and Encryption | the user authentication mode to be used by TM1. | ||
| IPAddressV4 | 🔄 | Network | IPv4 address for an individual TM1 service. | |
| IPAddressV6 | 🔄 | Network | IPv6 address for an individual TM1 service. | |
| IPVersion | ipv4 | 🔄 | Network | Internet Protocol version used by TM1 to identify IP addresses on the network. |
| JavaClassPath | 🔄 | Java | parameter to make third-party Java™ libraries available to TM1. | |
| JavaJVMArgs | 🔄 | Java | list of arguments to pass to the Java Virtual Machine (JVM). Arguments are separated by a space and the dash character. For example JavaJVMArgs=-argument1=xxx -argument2=yyy. | |
| JavaJVMPath | 🔄 | Java | path to the Java Virtual Machine .dll file (jvm.dll) which is required to run Java from TM1 TurboIntegrator. | |
| keyfile | 🔄 | Authentication and Encryption | file path to the key database file. The key database file contains the server certificate and trusted certificate authorities. The server certificate is used by TM1 and the Admin server. | |
| keylabel | 🔄 | Authentication and Encryption | label of the server certificate in the key database file. | |
| keystashfile | 🔄 | Authentication and Encryption | file path to the key database password file. The key database password file is the key store that contains the password to the key database file. | |
| Language | 🔄 | Logs and Messages | language used for TM1. This parameter applies to messages generated by the server and is also used in the user interface of the server dialog box when you run the server as an application instead of a Windows service. | |
| LDAPHost | localhost | 🔄 | Authentication and Encryption | domain name or dotted string representation of the IP address of the LDAP server host. |
| LDAPPasswordFile | 🔄 | Authentication and Encryption | password file used when LDAPUseServerAccount is not used. This is the full path of the .dat file that contains the encrypted password for the Admin Server's private key. | |
| LDAPPasswordKeyFile | 🔄 | Authentication and Encryption | password key used when LDAPUseServerAccount is not used. | |
| LDAPPort | 389 | 🔄 | Authentication and Encryption | port TM1 uses to bind to an LDAP server. |
| LDAPSearchBase | 🔄 | Authentication and Encryption | node in the LDAP tree where TM1 begins searching for valid users. | |
| LDAPSearchField | cn | 🔄 | Authentication and Encryption | The name of the LDAP attribute that is expected to contain the name of TM1 user being validated. |
| LDAPSkipSSLCertVerification | F | 🔄 | Authentication and Encryption | Skips the certificate trust verification step for the SSL certificate used to authenticate to an LDAP server. This parameter is applicable only when LDAPVerifyServerSSLCert=T. |
| LDAPSkipSSLCRLVerification | F | 🔄 | Authentication and Encryption | Skips CRL checking for the SSL certificate used to authenticate to an LDAP server. This parameter is applicable only when LDAPVerifyServerSSLCert=T. |
| LDAPTimeout | 0 | Authentication and Encryption | number of seconds that TM1 waits to complete a bind to an LDAP server. If the LDAPTimeout value is exceeded TM1 immediately aborts the connection attempt. | |
| LDAPUseServerAccount | 🔄 | Authentication and Encryption | Determines if a password is required to connect to TM1 when using LDAP authentication. | |
| LDAPVerifyCertServerName | F | 🔄 | Authentication and Encryption | server to use during the SSL certificate verification process for LDAP server authentication. This parameter is applicable only when LDAPVerifyServerSSLCert=T. |
| LDAPVerifyServerSSLCert | F | 🔄 | Authentication and Encryption | Delegates the verification of the SSL certificate to TM1. This parameter is useful for example when you are using LDAP with a proxy server. |
| LDAPWellKnownUserName | 🔄 | Authentication and Encryption | user name used by TM1 to log in to LDAP and look up the name submitted by the user. | |
| LoadPrivateSubsetsOnStartup | F | 🔄 | Subsets | This configuration parameter determines if private subsets are loaded when TM1 starts. |
| LoadPublicViewsAndSubsetsAtStartup | T | 🔄 | Views | Added in v2.0.8 This configuration parameter enables whether public subsets and views are loaded when the TM1 starts and keeps them loaded to avoid lock contention during the first use. |
| LockPagesInMemory | F | 🔄 | deprecated | Deprecated as of IBM TM1 with Watson version 2.0.9.7 When this parameter is enabled memory pages used by TM1 process are held in memory (locked) and do not page out to disk under any circumstances. This retains the pages in memory over an idle period making access to TM1 data faster after the idle period. |
| LoggingDirectory | 🔄 | Logs and Messages | directory to which TM1 saves its log files. | |
| LogReleaseLineCount | 5000 | Logs and Messages | number of lines that a search of the Transaction Log will accumulate in a locked state before releasing temporarily so that other Transaction Log activity can proceed. | |
| MagnitudeDifferenceToBeZero | 🔄 | Calculations | order of magnitude of the numerator relative to the denominator above which the denominator equals zero when using a safe division operator. | |
| MaskUserNameInServerTools | T | 🔄 | Logs and Messages | Determines whether usernames in server administration tools are masked until a user is explicitly verified as having administrator access. |
| MaximumCubeLoadThreads | 0 | 🔄 | Multithreading | Specifies whether the cube load and feeder calculation phases of server loading are multi-threaded so multiple processor cores can be used in parallel. |
| MaximumLoginAttempts | 3 | Authentication and Encryption | maximum number of failed user login attempts permissible on TM1. | |
| MaximumMemoryForSubsetUndo | 10240 | Cache | maximum amount of memory in kilobytes to be dedicated to storing the Undo/Redo stack for the Subset Editor. | |
| MaximumSynchAttempts | 1 | 🔄 | Network | maximum number of times a synchronization process on a planet database will attempt to reconnect to a network before the process fails. |
| MaximumTILockObjects | 2000 | 🔄 | Turbo Integrator | This configuration parameter sets the maximum lock objects for a TurboIntegrator process. Used by the synchronized() TurboIntegrator function. |
| MaximumUserSandboxSize | 500 MB | Sandboxes | maximum amount of RAM memory (in MB) to be allocated per user for personal workspaces or sandboxes. | |
| MaximumViewSize | 500 MB | Views | maximum amount of memory (in MB) to be allocated when a user accesses a view. | |
| MDXSelectCalculatedMemberInputs | T | MDX | Changes the way in which calculated members in MDX expressions are handled when zero suppression is enabled. | |
| MemoryCache.LockFree | F | Cache | Switches global garbage collection to use lock free structures. | |
| MessageCompression | T | 🔄 | Network | Enables message compression for large messages that significantly reduces network traffic. |
| MTCubeLoad | F | Multithreading | Enables multi-threaded loading of individual cubes. | |
| MTCubeLoad.MinFileSize | 10KB | Multithreading | minimum size for cube files to be loaded on multiple threads. | |
| MTCubeLoad.UseBookmarkFiles | F | Multithreading | Enables the persisting of bookmarks on disk. | |
| MTCubeLoad.Weight | 10 | Multithreading | number of atomic operations needed to load a single cell. | |
| MTFeeders | F | Multithreading | Applies multi-threaded query parallelization techniques to the following processes: the CubeProcessFeeders TurboIntegrator function cube rule updates and construction of multi-threaded (MT) feeders at start-up. | |
| MTFeeders.AtStartup | F | Multithreading | If the MTFEEDERS configuration option is enabled enabling MTFeeders.AtStartup applies multi-threaded (MT) feeder construction during server start-up. | |
| MTFeeders.AtomicWeight | 10 | Multithreading | number of required atomic operations to process feeders of a single cell. | |
| MTQ | -1 | Multithreading | maximum number of threads per single-user connection when multi-threaded optimization is applied. Used when processing queries and in batch feeder and cube load operations. | |
| MTQ.OperationProgressCheckSkipLoopSize | 10000 | Multithreading | fine-tune multi-threaded query processing. | |
| MTQ.SingleCellConsolidation | T | Multithreading | fine-tune multi-threaded query processing. | |
| MTQQuery | T | Multithreading | enable multi-threaded query processing when calculating a view to be used as a TurboIntegrator process datasource. | |
| NetRecvBlockingWaitLimitSeconds | 0 | 🔄 | Network | have the database perform the wait period for a client to send the next request as a series of shorter wait periods. This parameter changes the wait from one long wait period to shorter wait periods so that a thread can be canceled if needed. |
| NetRecvMaxClientIOWaitWithinAPIsSeconds | 0 | 🔄 | Network | maximum time for a client to do I/O within the time interval between the arrival of the first packet of data for a set of APIs through processing until a response has been sent. |
| NIST_SP800_131A_MODE | T | 🔄 | Authentication and Encryption | the database must operate in compliance with the SP800-131A encryption standard. |
| ODBCLibraryPath | 🔄 | ODBC | name and location of the ODBC interface library (.so file) on UNIX. | |
| ODBCTimeoutInSeconds | 0 | ODBC | timeout value that is sent to the ODBC driver using the SQL_ATTR_QUERY_TIMEOUT and SQL_ATTR_CONNECTION_TIMEOUT connection attributes. | |
| OptimizeClient | 0 | Cache | Added in v2.0.7 This parameter determines whether private objects are loaded when the user authenticates during TM1 startup. | |
| OracleErrorForceRowStatus | 0 | 🔄 | ODBC | ensure the correct interaction between TurboIntegrator processes and Oracle ODBC data sources. |
| PasswordMinimumLength | Authentication and Encryption | minimum password length for clients accessing TM1. | ||
| PasswordSource | TM1 | 🔄 | Authentication and Encryption | Compares user-entered password to the stored password. This parameter is applicable only to TM1s on cloud or local. It is not applicable to TM1 Engine in Cloud Pak for Data or Amazon Web Services. |
| PerfMonIsActive | T | Logs and Messages | turn updates to TM1 performance counters on or off. | |
| PerformanceMonitorOn | F | Logs and Messages | Automatically starts populating the }Stats control cubes when a TM1 starts. | |
| PersistentFeeders | F | 🔄 | Rules | To improve reload time of cubes with feeders set the PersistentFeeders configuration parameter to true (T) to store the calculated feeders to a .feeders file. |
| PortNumber | 12345 | 🔄 | Network | server port number used to distinguish between multiple TM1s running on the same computer. |
| PreallocatedMemory.BeforeLoad | F | Cache | Added in v2.0.5 Specifies whether the preallocation of memory occurs before TM1 loading or in parallel. | |
| PreallocatedMemory.Size | 0 | Cache | Added in v2.0.5 Triggers the preallocation of pooled TM1 memory. | |
| PreallocatedMemory.ThreadNumber | 4 | Multithreading | Added in v2.0.5 Specifies the number of threads used for preallocation memory in multi-threaded cube loading. | |
| PrivilegeGenerationOptimization | F | 🔄 | Cache | When TM1 generates security privileges from a security control cube it reads every cell from that cube. |
| ProgressMessage | T | 🔄 | Logs and Messages | whether users have the option to cancel lengthy view calculations. |
| ProportionSpreadToZeroCells | T | 🔄 | Logs and Messages | Allows you to perform a proportional spread from a consolidation without generating an error when all the leaf cells contain zero values. |
| PullInvalidationSubsets | T | Subsets | Reduces metadata locking by not requiring an R-lock (read lock) on the dimension during subset creation deletion or loading from disk. | |
| RawStoreDirectory | Logs and Messages | location of the temporary unprocessed log file for audit logging if logging takes place in a directory other than the data directory. | ||
| ReceiveProgressResponseTimeoutSecs | Network | The ReceiveProgressResponseTimeoutSecs parameter configures TM1 to sever the client connection and release resources during a long wait for a Cancel action. | ||
| ReduceCubeLockingOnDimensionUpdate | F | 🔄 | Dimensions | Reduces the occurrence of cube locking during dimension updates. |
| RulesOverwriteCellsOnLoad | F | 🔄 | Rules | Prevents cells from being overwritten on TM1 load in rule-derived data. |
| RunningInBackground | F | 🔄 | Linux | When you add the line RunningInBackground=T to TM1 configuration TM1 on UNIX runs in background mode. |
| SaveFeedersOnRuleAttach | T | Rules | When set to False postpones writing to feeder files until SaveDataAll and CubeDataSave are called instead of updating the files right after rules are changed and feeders are generated at TM1 start time. | |
| SaveTime | Chores | time of day to execute an automatic save of TM1 data; saves the cubes every succeeding day at the same time. As with a regular shutdown SaveTime renames the log file opens a new log file and continues to run after the save. | ||
| SecurityPackageName | 🔄 | Authentication and Encryption | If you configure TM1 to use Integrated Login the SecurityPackageName parameter defines the security package that authenticates your user name and password in MS Windows. | |
| ServerCAMURI | Cognos Analytics | URI for the internal dispatcher that TM1 should use to connect to Cognos Authentication Manager (CAM). | ||
| ServerCAMURIRetryAttempts | 3 | 🔄 | Cognos Analytics | number of attempts made before moving on to the next ServerCAMURI entry in TM1 configuration. |
| ServerLogging | F | Logs and Messages | Generates a log with the security activity details on TM1 that are associated with Integrated Login. | |
| ServerName | 🔄 | Network | name of the server. If you do not supply this parameter TM1 names the server Local and treats it as a local server. | |
| ServicePrincipalName | 🔄 | Authentication and Encryption | service principal name (SPN) when using Integrated Login with TM1 Web and constrained delegation. | |
| SpreadErrorInTIDiscardsAllChanges | F | 🔄 | Turbo Integrator | If SpreadErrorInTIDiscardsAllChanges is enabled and a spreading error occurs as part of a running TurboIntegrator script all changes that were made by that TurboIntegrator script are discarded. |
| SpreadingPrecision | 1e-8 | Calculations | Use the SpreadingPrecision parameter to increase or decrease the margin of error for spreading calculations. The SpreadingPrecision parameter value is specified with scientific (exponential) notation. | |
| SQLRowsetSize | 50 | ODBC | Added in v2.0.3 Specifies the maximum number of rows to retrieve per ODBC request. | |
| SSLCertAuthority | 🔄 | Authentication and Encryption | name of TM1's certificate authority file. This file must reside on the computer where TM1 is installed. | |
| SSLCertificate | 🔄 | Authentication and Encryption | full path of TM1's certificate file which contains the public/private key pair. | |
| SSLCertificateID | 🔄 | Authentication and Encryption | name of the principal to whom TM1's certificate is issued. | |
| StartupChores | 🔄 | Chores | StartupChores is a configuration parameter that identifies a list of chores that run at database startup. | |
| SubsetElementBreatherCount | -1 | Subsets | handles locking behavior for subsets. | |
| SupportPreTLSv12Clients | F | 🔄 | Authentication and Encryption | As of TM1 10.2.2 Fix Pack 6 (10.2.2.6) all SSL-secured communication between clients and databases in TM1 uses Transport Layer Security (TLS) 1.2. This parameter determines whether clients prior to 10.2.2.6 can connect to the 10.2.2.6 or later TM1 server. |
| SvrSSLExportKeyID | 🔄 | Authentication and Encryption | identity key used to export TM1's certificate from the MS Windows certificate store. | |
| SyncUnitSize | 1000 | 🔄 | Network | frequency of saving a check point during a synchronization process in case there is a network connection failure. |
| tlsCipherList | 🔄 | Network | comma-separated list of supported cipher suites in priority sequence. | |
| TopLogging | F | Logs and Messages | Added in v2.0.7 Enables dynamic logging of the threads that are running in an instance of TM1. | |
| TopScanFrequency | 5 | Logs and Messages | Added in v2.0.7 Specifies the logging frequency (interval) in seconds for the TopLogging logger which enables dynamic logging of the threads that are running in an instance of TM1. | |
| TopScanMode.Sandboxes | F | Logs and Messages | Added in v2.0.7 Enables logging of the active sandboxes for the current TM1 the total memory that is consumed for all sandboxes by a user and the number of sandboxes for this user. | |
| TopScanMode.SandboxQueueMetrics | F | Logs and Messages | Added in v2.0.7 Enables logging of sandbox queue metrics. The name of the node for the sandbox the status of the sandbox in the queue and the length of time the sandbox was in the queue before it was processed is logged for each sandbox in the queue. | |
| TopScanMode.Threads | T | Logs and Messages | Added in v2.0.7 Enables logging of the current processing state of each thread. This information includes the name of the user or process that started the thread the API function that the thread is executing the lock status of the last object that was locked the number of objects that are used by the thread and the total time in seconds that the current API function or chore process has been processing. | |
| UnicodeUpperLowerCase | T | 🔄 | Logs and Messages | This configuration parameter instructs TM1 to identify and handle Unicode object names preventing the creation of identical Unicode object names that vary only in case. |
| UseExcelSerialDate | F | 🔄 | Calculations | Enables the use of MS Excel serial dates instead of TM1 serial dates. |
| UseLocalCopiesforPublicDynamicSubsets | T | Subsets | Allows public dynamic subsets to improve performance and reduce locking by using local copies of the subset when possible. | |
| UserDefinedCalculations | T | Subsets | Enables the Rollup and Insert Subset options to create user-defined consolidations in the Subset Editor in TM1 and enables the Create Custom Consolidation button in TM1(r)Web clients. | |
| UseSQLFetch UseSQLFetchScroll UseSQLExtendedFetch | F | ODBC | These parameters instruct TM1 to use a particular fetch call. | |
| UseSSL | T | 🔄 | Authentication and Encryption | Enables or disables SSL on TM1. |
| UseStargateForRules | T | 🔄 | Rules | rules use Stargate views. |
| VersionedListControlDimensions | T | 🔄 | Dimensions | Removes contention on control dimensions such as }Cubes }Dimensions }Groups }Clients. Allows creation of new objects without IX locking the dimension. |
| ViewConsolidationOptimization | T | 🔄 | Views | Enables or disables view consolidation optimization on TM1. |
| ViewConsolidationOptimizationMethod | TREE | 🔄 | Views | method used to achieve view consolidation optimization when the ViewConsolidationOptimization parameter is enabled on TM1. |
| ZeroWeightOptimization | T | 🔄 | Calculations | Determines whether consolidated members with a weight of 0 are factored into the computation of consolidated cell values or consolidation functions. Consolidation functions include ConsolidatedCount ConsolidatedMax ConsolidatedMin ConsolidatedAvg ConsolidatedCount and ConsolidatedCountUnique. |