
MDX
MDX
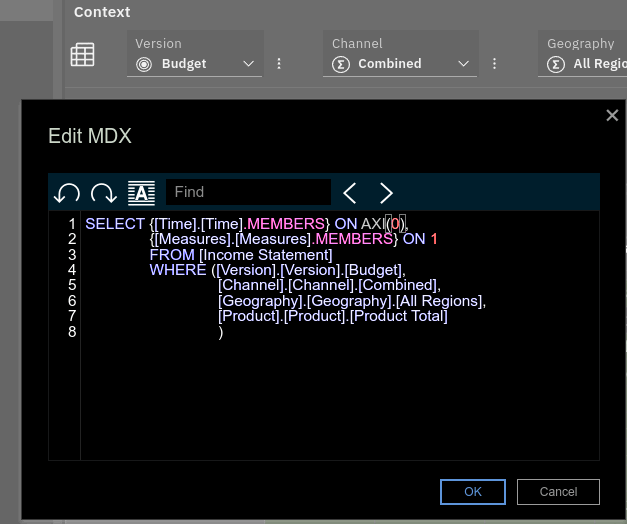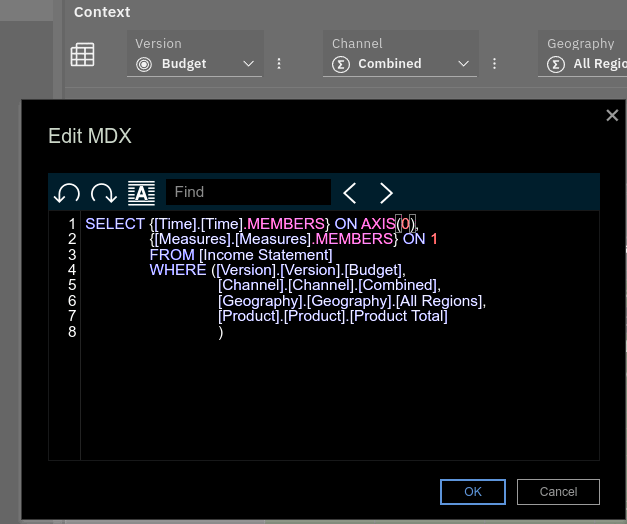
Duplicate Elements in Rollups
Large nested rollups can lead to elements being counted twice or more within a rollup.
The following process helps you to find, across all dimensions of your system, all rollups that contain elements consolidated more than once under the rollup.
The code isn't the cleanest and there are probably better methods to achieve the same result so don't hesitate to edit the page or comment.
It proceeds like this:
Comments
Comments allow you to explain, to yourself and/or to your users, what the query is trying to achieve, how it works, who wrote it or amended, etc.
Use "//" or "—" (without the double quotes) to end a line with a comment or to have the comment on its own line.
You can also use “/* COMMENT */” (again without the quotes) to insert a comment in the middle of a
line. You are also able to type anything after the command.
Syntax and Layout
A query can be broken over multiple lines to make it more readable. For example:
{
FILTER(
{TM1FILTERBYLEVEL( {TM1SUBSETALL( [Product] )}, 0)},
Test2.([Rate Measures].[Rate]) = 19
)
}
is more readable than having the whole query in one line. The actual filter section is more easily read and modified now by having it on a line by itself.
A closer look at subsets
if you ever loaded a .sub file (subset) in an editor this is the format you would expect:
Creating Dynamic Subsets in Applix TM1 with MDX - A Primer
Lead author: Philip Bichard.
Additional Material: Martin Findon.
About This Document
This MDX Primer is intended to serve as a simple introduction to creating dynamic dimension subsets using MDX in TM1. It focuses on giving working examples rather than trying to explain the complete theory of MDX and makes sure to cover the features most useful to TM1 users.
Count and IIF
Caveat: Note that IIF is not listed in the TM1 v9.0 SP2 help file as being supported so use at your own risk.
Count returns the number of items in a set but this set can be a set of members or a set of data values. The result is, obviously, a number and is often returned in reports when used in MDX queries outside of TM1. When trying to use it do define a TM1 subset it can only be used as part of the query logic and not as a result itself.
Generate
The Generate function applies a second set to each member of a first set, performing a union of the results. Duplicates are dropped by default but can be retained with “,ALL”.
Although Generate doesn’t really do anything unique in itself it is a very useful way of shortening what would otherwise be long, laborious and error-prone queries.
Using parameters in queries
TM1Member will allow you to use parameterized references by using cube values as part of the query itself.
Data-based queries, Filter, Sum, Avg and Stdev
Sometimes it is not adequate to simply use a single value in a query; you need to consider a combination of values. It might be that this combination is only needed for one or two queries, though, so it is not desirable to calculate and store the result in the cube for all to see. Therefore it is more logical to quickly calculate the result on the fly and although this is then repeated every time the subset is used, it is still the preferred choice.