Users
UsersTips for TM1 users:
Cube Viewer tips
Cube Viewer tipsColumns width
When you have a view with a lot of dimensions displayed, it happens that most of the screen estate is consumed by the dimensions columns and you find yourself scrolling a lot left and right to read the data points.
To ease that problem:
-
choose the shortest aliases for all dimensions from the subset editor
-
choose subset names as short as possible
-
uncheck the Options->Expand Row Header
Excel/Perspectives Tips
Excel/Perspectives TipsSynchronising Excel data
. to reduce the probability of crashing your Excel, disable Automatic Calculation : Go to Tools->Options-> Calculation Tab then click on the Manual button
You can use:
- F9 to manually refresh all the open workbooks
- Shift F9 to refresh only the current worksheet
- F2 and Enter key (i.e. edit cell) to refresh only 1 cell
In TM1 9.4.1, the spreadsheets will recalculate automatically when opening a workbook, or changing a SUBNM despite automatic calc is disabled.
From the Excel top menu, click Insert->Name->Define
.In the Define Name dialog box, input TM1REBUILDOPTION
.Set the value in the Refers to box to 0 and click OK.
Avoid multiple dynamic slices
Multiple dynamic TM1 slices in several sheets in a workbook might render Excel unstable and crash. Some references might get messed up too.
E10) Data directory not found
If you are getting the e10) data directory not found popup error when loading Perspectives, you need to define the data directory of your local server, even if you do not want to run a local server.
Go to Files->Options and enter a valid folder in the Data Directory box. if that box is greyed out then you need to edit manually the variable in your tm1p.ini stored on your PC.
DataBaseDirectory= C:\some\path\
Alternatively you can modify the setting directly from Excel with the following VBA code:
Application.Run("OPTSET", "DatabaseDirectory", "C:\some\path")
Publish Views
Publish ViewsPublishing users' view is still far from a quick and simple process in TM1.
First, the admin cannot see other users' views.
Second, users cannot publish their own views themselves.
So publishing views always require a direct intervention from the admin, well not anymore :)
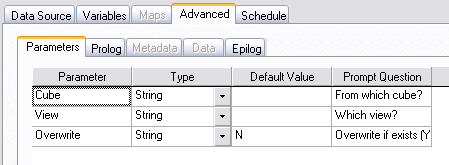
1. create a process with the following code
in Advanced->Parameters Tab
in the Advanced->Prolog Tab
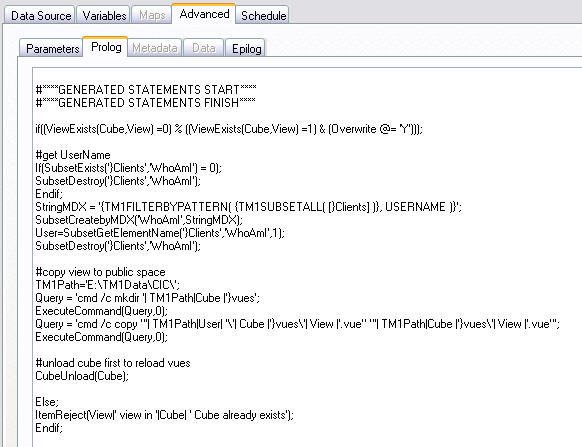
if((ViewExists(Cube,View) =0) % ((ViewExists(Cube,View) =1) & (Overwrite @= 'Y')));
#get UserName
If(SubsetExists('}Clients','WhoAmI') = 0);
SubsetDestroy('}Clients','WhoAmI');
Endif;
StringMDX = '{TM1FILTERBYPATTERN( {TM1SUBSETALL( [}Clients] )}, USERNAME )}';
SubsetCreatebyMDX('WhoAmI',StringMDX);
User=SubsetGetElementName('}Clients','WhoAmI',1);
SubsetDestroy('}Clients','WhoAmI');
#copy view to public space
TM1Path='E:\TM1Data\TM1Server\';
Query = 'cmd /c mkdir '| TM1Path|Cube |'}vues';
ExecuteCommand(Query,0);
Query = 'cmd /c copy "'| TM1Path|User| '\'| Cube |'}vues\'| View |'.vue" "'| TM1Path|Cube |'}vues\'| View |'.vue"';
ExecuteCommand(Query,0);
#unload cube first to reload vues
CubeUnload(Cube);
Else;
ItemReject(View|' view in '|Cube| ' Cube already exists');
Endif;
2. change the TM1Path and save
3. in Server Explorer, Process->Security Assignment, set that process as Read for all groups that should be allowed to publish
Now your users can publish their views on their own by executing this process, they just need to enter the name of the cube and the view to publish.
Alternatively, the code in the above Prolog Tab can be simplified and replaced with these 5 lines:
if((ViewExists(Cube,View) =0) % ((ViewExists(Cube,View) =1) & (Overwrite @= 'Y'))); PublishView(Cube,View,1,1); Else; ItemReject(View|' view in '|Cube| ' Cube already exists'); Endif;
Subset Editor
Subset EditorTree View
To display consolidated elements below their children: View -> Expand Above
Faster Subset Editor
In order to get a faster response from the subset editor, disable the Properties Window:
View -> Properties Window
or click the "Display Properties Window" from the toolbar
Updating an existing subset
to add one or more elements in an existing subset without recreating it:
from the subset editor
- Edit->Insert Subset
- Select the elements
- Click OK to Save as private Subset1
now Subset1 is added to your existing subset
- Expand Subset1
- Click on the Subset1 consolidation element then delete
- You can now save your subset with the new elements
TM1Web
TM1Web- To get cube views to display much faster in tm1web: subsets of the dimensions at the top must contain only 1 element each
- Clicking on the icons in the Export dropdown menu will have no effect, only clicking on the associated text on the right "slice/snapshot/pdf" will start an export
Tracing TM1 references
Tracing TM1 referencesHomemade TM1 reports can get quite convoluted and users might get a hard time updating them as it is difficult to tell where some TM1 formulas are pointing to.
The excel formula auditing toolbar can be useful in such situations.
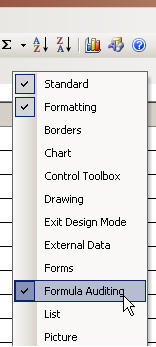
- right click next to the top bar to bring up the bars menu
- select "Formula Auditing" bar
- Activate tracing arrows to highlight precedents
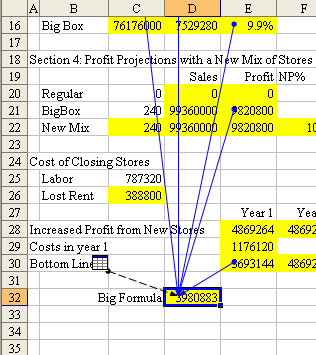
This is quite useful to get the scope of a cube or dimension reference in a report or to see which elements a DBRW formula is made of.